How Agents Learn: Context Files and Skills
Agents learn through three mechanisms, each with different loading behavior and context cost. Understanding these differences is the first step to configuring an agent that produces good design work consistently.
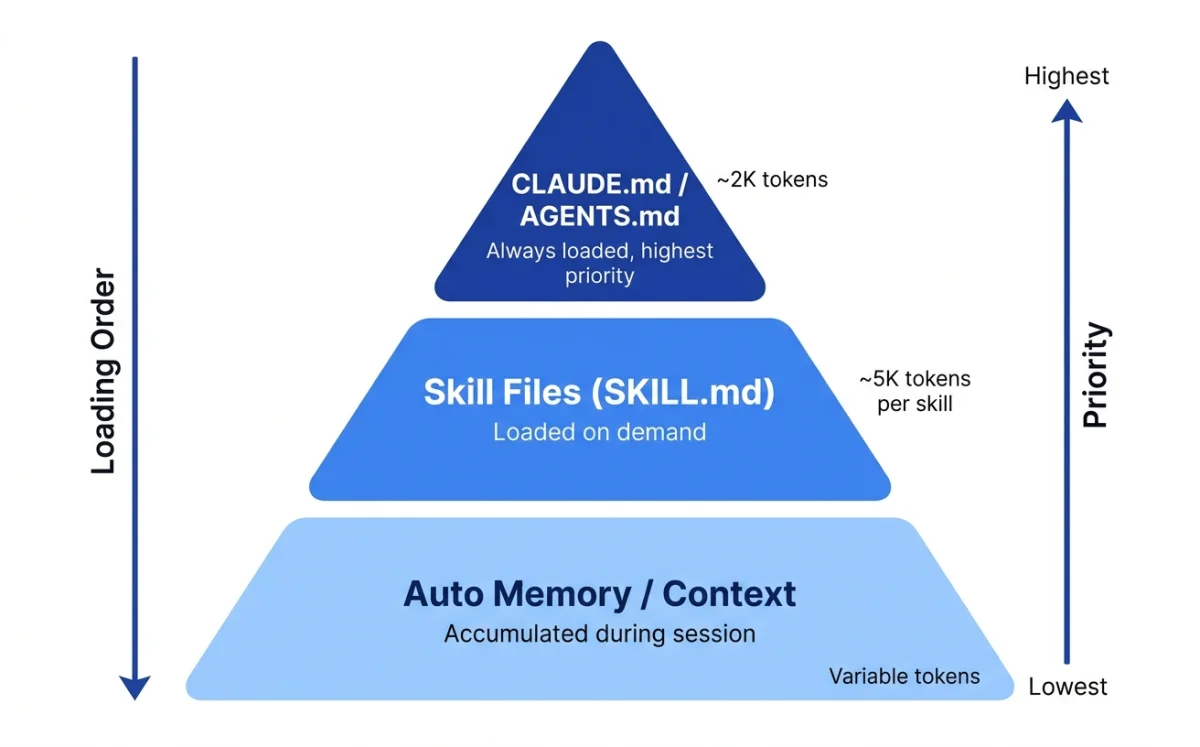
| Mechanism | When loaded | Context cost | Scope |
|---|---|---|---|
| Configuration files (CLAUDE.md, AGENTS.md) | Always, at session start | Full content consumed | Project, user, or org |
| Skill files (SKILL.md) | On demand, when invoked or matched | Near-zero until used | Per-skill, per-task |
| Auto memory (Claude Code only) | At session start, accumulated over time | First 200 lines loaded | Per-project |
The distinction matters more than it first appears. Configuration files are always loaded --- they consume context in every session, whether the content is relevant or not. This means every line in your CLAUDE.md or AGENTS.md has an ongoing cost. Keep them short. Keep them factual. Move procedures elsewhere.
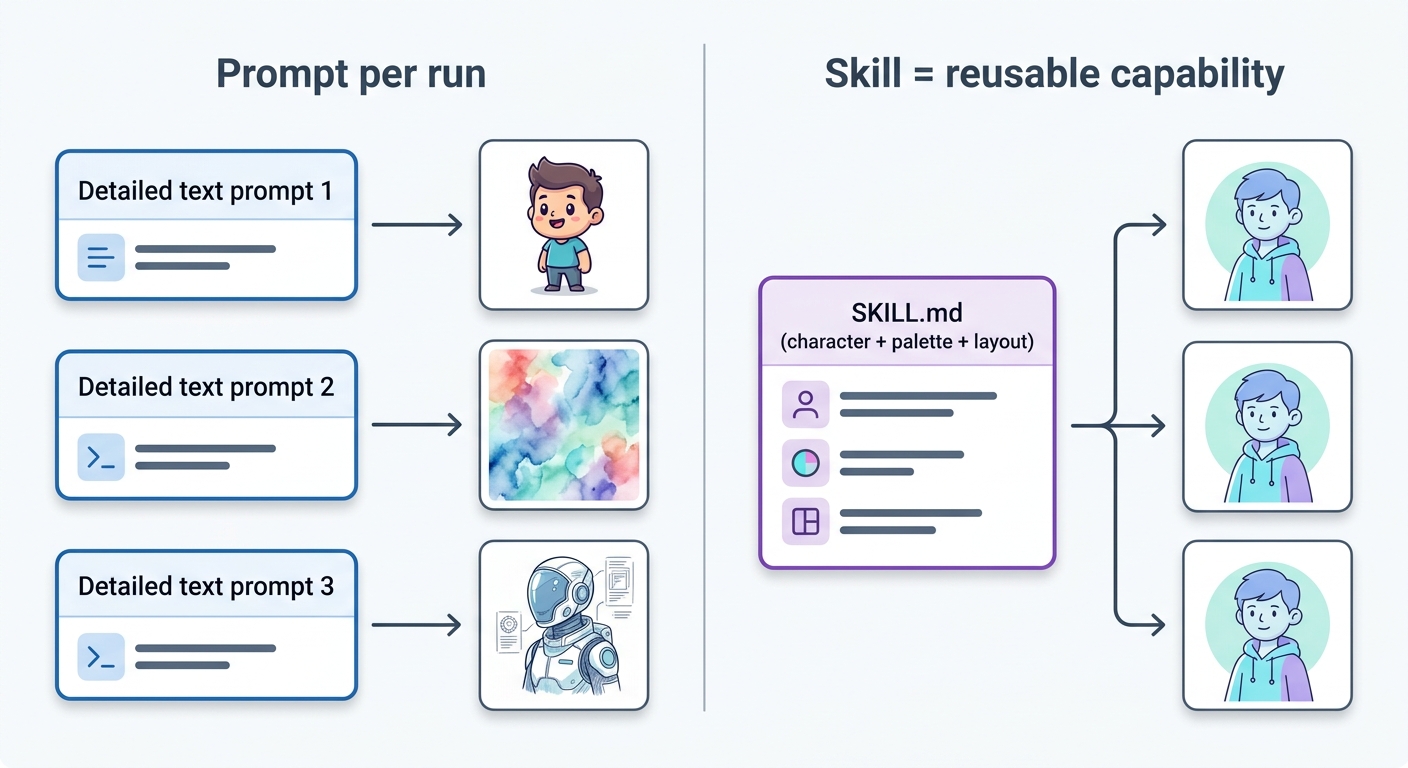
Think of it this way: the configuration file is the agent's long-term memory. It always has access to it. The skill file is the agent's reference library. It pulls a book off the shelf only when it needs to look something up. Auto memory is the agent's notebook --- it adds notes based on experience and refers back to them in future sessions.
Skills load on demand --- they consume context only when invoked. This makes skills the right place for lengthy reference material. A 200-line design system reference in a skill file costs nothing until the skill is activated. The same 200 lines in CLAUDE.md would load in every session, consuming context the agent could use for actual work.
From the Claude Code documentation: "Unlike CLAUDE.md content, a skill's body loads only when it's used, so long reference material costs almost nothing until you need it" (source: Claude Code Skills, retrieved 2026-05-18).
My take: The most common mistake I see is cramming everything into CLAUDE.md. Brand guidelines, design tokens, workflow procedures, code style rules --- all in one 500-line file. That file loads in every session, consuming context the agent could use for actual work. Move procedures to skills. Keep CLAUDE.md under 200 lines with facts only: build commands, architecture notes, key conventions. This is not a suggestion. It is a rule Claude Code's own documentation states explicitly.
CLAUDE.md and AGENTS.md Deep Dive
Two configuration file conventions exist. CLAUDE.md is Claude Code's native format. AGENTS.md is used by Codex CLI and OpenCode. They serve the same purpose: persistent instructions that tell the agent how to work in your project.
The good news: they are cross-compatible. OpenCode reads CLAUDE.md as a fallback. Claude Code can import AGENTS.md with the @AGENTS.md syntax. You do not need to choose one or the other.
CLAUDE.md Hierarchy
Claude Code loads CLAUDE.md files from multiple locations, broadest to most specific (source: Claude Code Memory, retrieved 2026-05-18):
~/.claude/CLAUDE.md # User-level (personal, all projects)
./CLAUDE.md # Project-level (committed to git)
./.claude/CLAUDE.md # Project-level (alternative location)
./CLAUDE.local.md # Local personal (gitignored)
.claude/rules/design-components.md # Path-scoped rulesFiles in parent directories load in full at launch. Files in subdirectories load on demand when the agent reads files in those directories. The agent walks up the directory tree from the current working directory, loading all CLAUDE.md files it finds. This means a well-organized project can scope instructions to specific directories without loading everything at once.
The .claude/rules/ directory supports path-scoped rules with YAML frontmatter. A rule that applies only to CSS and HTML files:
---
paths:
- "src/components/**/*.tsx"
- "src/styles/**/*.css"
---
# Design Component Rules
- All components must follow the design system
- Use CSS custom properties for theming
- Ensure accessible color contrast (WCAG AA)Path-scoped rules load only when the agent touches matching files. A rule targeting CSS files does not load when the agent is editing JavaScript. This keeps the context clean and focused.
AGENTS.md for Codex and OpenCode
AGENTS.md follows a simpler model than CLAUDE.md. From the Codex system message: "The scope of an AGENTS.md file is the entire directory tree rooted at the folder that contains it. More-deeply-nested AGENTS.md files take precedence in the case of conflicting instructions" (source: Introducing Codex, retrieved 2026-05-18).
Codex adds a requirement not found in CLAUDE.md: "If the AGENTS.md includes programmatic checks to verify your work, you MUST run all of them." This makes AGENTS.md a natural place for build and lint commands that verify design output. Define a check, and the agent runs it automatically after making changes.
OpenCode reads AGENTS.md as the primary convention and falls back to CLAUDE.md if no AGENTS.md exists (source: OpenCode Rules, retrieved 2026-05-18). The /init command auto-generates AGENTS.md by scanning the repository:
# Auto-generated by /init
# SST v3 Monorepo Project
This is an SST v3 monorepo with TypeScript. The project uses bun workspaces.
## Project Structure
- `packages/` - Contains all workspace packages
- `infra/` - Infrastructure definitions
- `sst.config.ts` - Main SST configuration
## Code Standards
- Use TypeScript with strict mode enabled
- Shared code goes in `packages/core/`
## Build Commands
- Dev: `bun run dev`
- Build: `bun run build`
- Test: `bun test`The auto-generated file is a starting point. Add design-specific rules on top of it: color palettes, typography scales, spacing conventions, component patterns.
The key difference between CLAUDE.md and AGENTS.md is philosophical, not technical. CLAUDE.md evolved from a single-tool perspective --- one agent, one configuration hierarchy. AGENTS.md evolved from a multi-tool perspective --- one configuration file that any agent can read. In practice, the distinction matters less than the content. Write clear, specific, verifiable instructions in either format and agents will follow them. Write vague instructions and agents will guess, often incorrectly.
What makes a good configuration file for design work? Specificity. "Use accessible colors" is vague. "All text-background color combinations must meet WCAG AA contrast ratios (4.5:1 for normal text, 3:1 for large text)" is specific and verifiable. "Follow the brand style" is vague. "Primary color: var(--primary), Secondary color: var(--secondary), Headings: Inter Bold, Body: Inter Regular, Font scale: 12/14/16/20/24/32/48px" is specific. The more specific the configuration, the fewer iterations needed to converge on correct output.
Another principle: verifiability. Codex's AGENTS.md spec includes a powerful feature --- programmatic checks. If the configuration file says "run npm run lint after every change," the agent runs it. If the check fails, the agent fixes the issue. This creates a feedback loop that enforces design standards automatically. Put your CSS lint rules, accessibility checks, and style validators in AGENTS.md, and the agent enforces them without being asked.
Cross-Compatibility
CLAUDE.md and AGENTS.md can coexist in the same project. Two approaches work well.
Import pattern (Claude Code reads AGENTS.md):
# CLAUDE.md
@AGENTS.md
## Claude Code Specific
Use plan mode for changes under `src/billing/`.The @AGENTS.md import pulls the full content of AGENTS.md into CLAUDE.md. Claude Code sees both files as a single instruction set. Add Claude Code-specific rules below the import.
Symlink pattern (shared file): Create a symlink from CLAUDE.md to AGENTS.md (ln -s AGENTS.md CLAUDE.md). This makes the same file accessible under both names. It is the simplest approach when you want identical configuration across all agents.
OpenCode handles cross-compatibility automatically. If AGENTS.md exists, it uses that. If only CLAUDE.md exists, it reads CLAUDE.md instead. No configuration needed on your part.
For teams, I recommend the import pattern. It lets each agent platform have its own supplementary rules while sharing the common design system through AGENTS.md. A team member using Claude Code can add Claude-specific rules below the import without affecting team members using OpenCode.
Auto Memory
Claude Code writes its own notes across sessions. These accumulate in ~/.claude/projects/<project>/memory/:
~/.claude/projects/my-project/memory/
├── MEMORY.md # Concise index (first 200 lines loaded per session)
├── debugging.md # Detailed notes on recurring issues
└── api-conventions.md # Topic files (loaded on demand)Auto memory captures corrections and patterns. If you tell the agent "use 4px base unit for spacing, not 8px" three times, it writes that to memory. Future sessions load it automatically. This is the closest thing to "training" without fine-tuning the model.
For design work, auto memory is useful for capturing preferences that are too specific for CLAUDE.md but come up repeatedly. Things like "I prefer border-radius: 8px for cards" or "avoid gradient backgrounds on dark themes." These accumulated preferences compound over time.
Karpathy's CLAUDE.md: Four Rules, 65 Lines, 220k Stars
Andrej Karpathy's CLAUDE.md hit number one on GitHub trending in May 2026 with 220,000 stars. It is 65 lines long and contains four rules. The brevity is the point.
The four rules:
- Think before coding. Expose assumptions. Ask when unsure. Never guess.
- Simplicity first. Minimal code. No abstractions nobody asked for.
- Surgical changes. Do not touch unrelated code.
- Goal-oriented execution. Turn vague instructions into verifiable success criteria.
These rules are not specific to Claude Code. They apply to any agent session. But they crystallize something important about how to configure an agent for good output: the harness does not need to be long. It needs to constrain the right behaviors.
For design work, rule one maps to "don't start generating until you understand the visual direction." Rule two maps to "don't add design elements nobody asked for." Rule three maps to "when I ask you to change the hero section, don't also change the footer." Rule four maps to "when I say 'make it feel premium,' define what premium means in measurable terms before generating."
The popularity of this file tells you something about the ecosystem's direction. Early CLAUDE.md files were long and detailed. Karpathy's contribution demonstrates that a short, well-chosen set of constraints can outperform a comprehensive but unfocused harness. Quality of constraint matters more than quantity of constraint.
I don't use Karpathy's exact file. My CLAUDE.md files are longer because they include design-specific rules about token values, style preferences, and tool configurations. But the principle holds: every line in your harness should earn its place. If a rule does not change agent behavior in a measurable way, remove it.
The SKILL.md Convention
SKILL.md is the Agent Skills open standard (agentskills.io). It works across Claude Code and OpenCode. A skill is a directory containing a SKILL.md file with optional supporting files --- templates, examples, scripts.
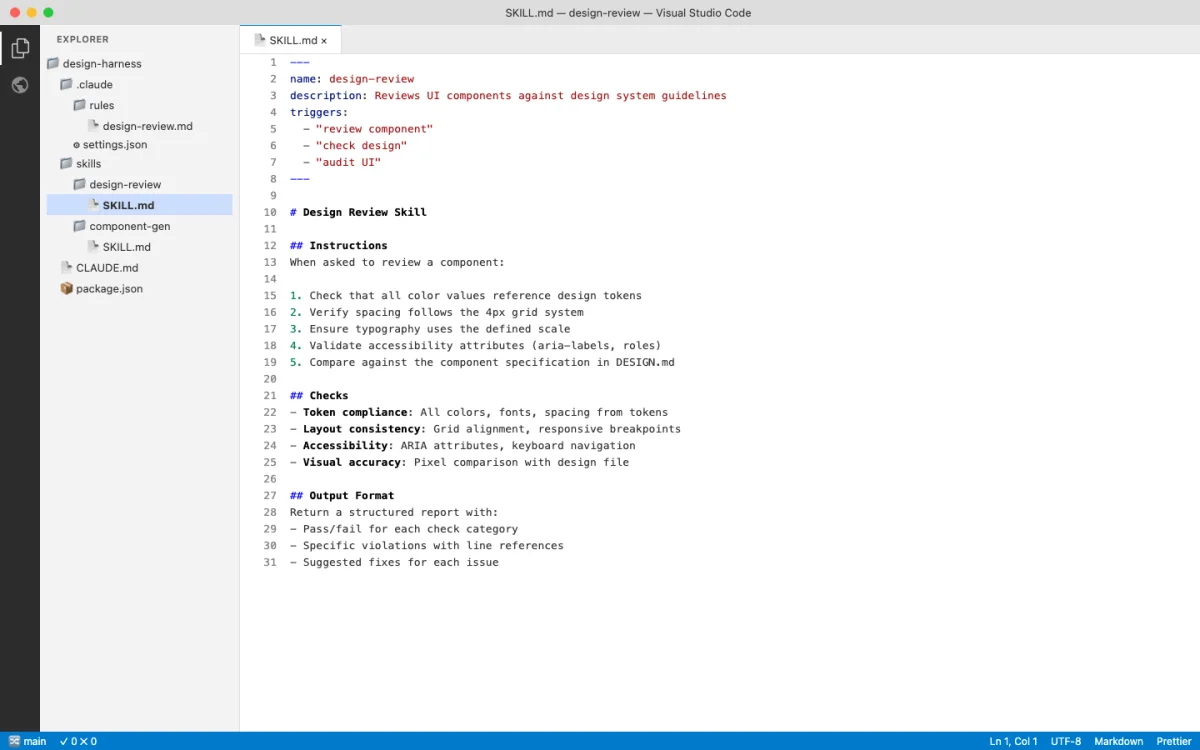
Skills solve the context cost problem. A design system reference might be 300 lines long. Put that in CLAUDE.md and it loads in every session. Put it in a skill file and it loads only when you invoke the skill. The difference in context efficiency is dramatic.
The skill system also solves a distribution problem. Skills can be shared. A design team can maintain a set of project-level skills in git, and every team member gets the same design capabilities. A community can publish skills that others install. The agentskills.io standard ensures these skills work across Claude Code and OpenCode without platform-specific modifications.
Skill Discovery Paths
Agents search for skills in multiple locations (source: OpenCode Skills, retrieved 2026-05-18):
| Path | Scope | Shared via git |
|---|---|---|
.opencode/skills/<name>/SKILL.md |
Project | Yes |
.claude/skills/<name>/SKILL.md |
Project | Yes |
.agents/skills/<name>/SKILL.md |
Project | Yes |
~/.claude/skills/<name>/SKILL.md |
User | No |
~/.agents/skills/<name>/SKILL.md |
User | No |
OpenCode searches all five paths. Claude Code searches .claude/skills/ and ~/.claude/skills/. Project-level skills can be committed to git and shared with the team. User-level skills are personal and available across all projects.
SKILL.md Structure
A skill file has two parts: YAML frontmatter that controls behavior, and a Markdown body that provides instructions to the agent.
---
name: brand-prototype
description: Generate brand-consistent HTML prototypes
when_to_use: Use when creating new UI mockups or prototypes
context: fork
agent: General
allowed-tools:
- read
- edit
- bash
---
## Brand Prototype Generator
Generate an HTML prototype for: $ARGUMENTS
Follow the brand design system in AGENTS.md.
Use inline CSS. No external dependencies.
Output a single HTML file.
## Steps
1. Read the design system from AGENTS.md
2. Read the component library from src/components/
3. Generate the HTML prototype
4. Validate accessibility (WCAG AA)Key frontmatter fields and what they control:
- name --- Must match the directory name. Lowercase, hyphens only. Used for invocation (
/brand-prototype). - description --- What the skill does. Used for auto-matching. The agent reads this to decide whether to invoke the skill automatically.
- context: fork --- Runs the skill in an isolated subagent. Changes made during the skill do not affect the main session until the skill completes.
- allowed-tools --- Pre-approves specific tools while the skill is active. The agent skips permission prompts for these tools.
- paths --- Glob patterns. The skill only activates when the agent touches matching files.
Dynamic Context Injection
Skills can execute commands before the agent sees the content. The !`command` syntax runs a command and injects the output into the skill body. This keeps the skill current without manual updates.
## Current Design Tokens
!`cat src/tokens.json`
## Recent Changes to Design System
!`git diff HEAD -- src/design/`Every time the skill activates, it pulls fresh data. The design tokens are always current. The recent changes are always up to date. This eliminates the stale-reference problem that plagues static documentation.
Skills also support argument substitution. The $ARGUMENTS variable captures everything after the skill name. Named arguments use $1, $2 syntax. Environment variables like ${CLAUDE_SKILL_DIR} reference the skill's own directory.
Installing and Composing Design Skills
Design skills exist at every level of the ecosystem. Some are general-purpose. Others are specialized for specific design outputs. The key insight: skills compose. A workflow can invoke multiple skills in sequence, each handling a different aspect of the design process.
Notable design skills available as of June 2026:
- huashu-design --- HTML-native design with 20 design philosophies and 5-dimension quality review. Produces production-grade prototypes, slide decks, and motion design. Covered in Chapter 07.
- frontend-design --- Production-grade frontend interfaces with high design quality. Avoids generic AI aesthetics through specific design principles.
- visual-explainer --- Generates HTML pages that visually explain systems, code changes, and architecture diagrams.
- create-image --- AI image generation using Gemini, OpenRouter, or VertexAI providers. Supports style references and templates.
- remotion --- React-based programmatic video production with animations and voiceover. Covered in Chapter 09.
- shadcn --- Component management for shadcn/ui projects. Adds, searches, fixes, and composes UI components.
TypeUI: A Design Skill Marketplace
TypeUI takes a different approach to design skill distribution. Instead of building one design tool, it ships a library of 67 design skills and 328 UI prompts that install directly into your coding agent. The platform supports Claude Code, Codex CLI, Cursor, OpenCode, Windsurf, and most other major agents (source: typeui.sh, retrieved 2026-06-04).
The install is a single command:
npx typeui generateThat gives your agent access to curated design systems, UI prompts, and layout variations. Each design skill defines a visual direction --- Brutalism, Neumorphism, Editorial, Skeumorphism, Glassmorphism --- with specific rules for typography, color, spacing, and composition. The UI prompts generate specific layout types: hero sections (25 variants), pricing tables (20 variants), feature sections (16 variants), navbars, sidebars, application shells.
The fundamental idea is the same one that powers Hallmark, Open Design, and every other design skill: constrain the agent's output by giving it a defined visual system to work within. TypeUI's contribution is breadth. With 67 skills and 328 prompts, it covers more visual territory than any single alternative. The CLI also includes randomize and update commands, which suggests an iterative workflow: generate with one skill, randomize to explore alternatives, update when the ecosystem adds new skills.
The pricing is notable. TypeUI charges $30/month or $120/year for Pro access, with a 50% discount for students and nonprofits. This is the first design skill platform I have seen with a commercial model at this scale. The free tier exists but is limited. Whether this model succeeds depends on whether teams find enough value in having a large skill library versus building their own focused skills.
The fundamentals skill is the one to start with:
npx skills add https://github.com/bergside/typeui --skill typeui-fundamentalsThis installs the base design rules that every TypeUI skill builds on. After that, you pull individual skills by slug:
npx typeui pull editorial
npx typeui pull brutalism
npx typeui pull glassmorphismFor the agentic design workflow, TypeUI fits in the skill layer of the stack. It does not replace Paper or Pencil or Figma. It gives your agent a richer vocabulary of visual directions to draw from when generating UI. Whether that vocabulary is worth paying for depends on how much time your team spends exploring visual directions versus refining a single direction.
Hallmark: Anti-Slop Guardrails as a Design Skill
Agent-generated UI has recognizable tells. Purple gradients. Emoji icons. Generic spacing that looks correct but feels empty. Rounded-corner cards with a left-border accent. SVG humans shaking hands. Inter used as a display font. Every team that has worked with AI-generated interfaces recognizes these patterns. They are the "AI design smell."
Hallmark is a design skill that refuses to look AI-generated. Version 1.1, released in May 2026, ships with 20 named themes and 57 slop-test gates that catch these patterns and force regeneration before the output reaches you (source: github.com/nutlope/hallmark, 2.6k stars, MIT license, retrieved 2026-06-04).
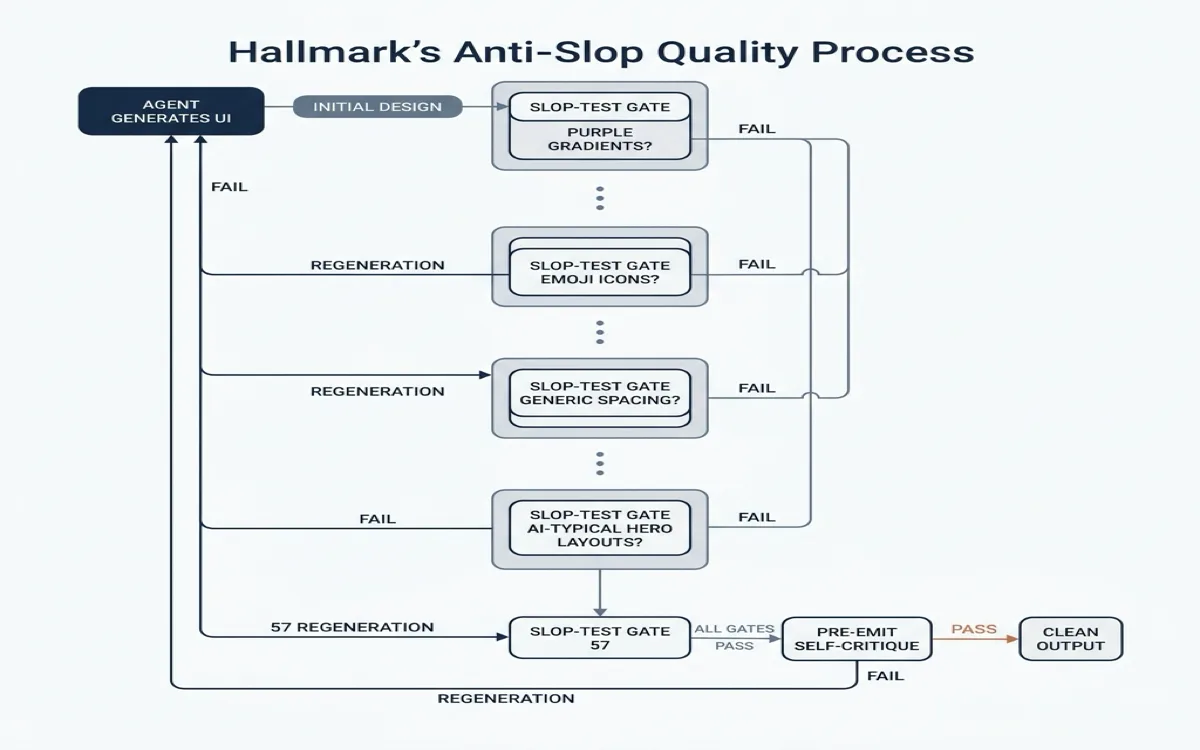
The skill operates on four verbs. Each verb is a different mode of use:
| Verb | What it does | When to use it |
|---|---|---|
| (default) | Build new UI. Picks a macrostructure, applies a theme, runs 57 slop gates and a self-critique. Regenerates if any gate fails. | Generating any new UI from scratch |
hallmark audit <target> | Score existing code against anti-patterns. Returns a punch list with scores. No edits. | Reviewing code the agent already generated, or auditing a legacy codebase |
hallmark redesign <target> | Throws out the visual structure, keeps copy + information architecture + brand, rebuilds with a different visual fingerprint. | When the content is right but the look is wrong |
hallmark study <screenshot | URL> | Extracts visual DNA from a design you admire: macrostructure, type pairing, color anchor. Optionally emits a portable design.md. | Learning from reference designs |
Install:
npx skills add nutlope/hallmarkManual install for other agents:
# Claude Code
cp -r hallmark ~/.claude/skills/hallmark/
# Cursor
cp hallmark/SKILL.md .cursor/rules/hallmark.mdc
# Codex CLI
cp -r hallmark ~/.codex/skills/hallmark/The 20 Named Themes
Each theme defines a complete visual system: macrostructure (layout grid, section ordering), type pairing (display + body fonts), color anchor (primary palette), and composition rules (spacing rhythm, element hierarchy). The 20 themes cover a wide range:
| Theme | Visual Character | Best For |
|---|---|---|
| Editorial | Serif display, clean body, strong hierarchy | Publications, blogs, content sites |
| Brutalism | Raw typography, exposed structure, no decoration | Portfolios, art projects, statement sites |
| Cobalt | Blue-primary corporate, tight spacing | Enterprise, SaaS, B2B |
| Carnival | Saturated warm palette, playful type | Events, entertainment, consumer apps |
| Lumen | Light-on-light, airy, generous whitespace | Lifestyle, wellness, minimal products |
| Hum | Warm neutrals, understated confidence | Consulting, agencies, professional services |
The full list of 20 is in the skill's CATALOG.md. The important point: each theme has been hand-tuned to avoid the 57 slop patterns. The theme is not just a color palette. It is a complete visual rule-set that constrains every design decision the agent makes.
Custom Mode
When a brief carries creative intent that no catalog theme fits, Hallmark switches to Custom mode and designs from scratch. Made-to-measure palette, type pairing, and layout. The same 57 slop-test gates still apply. No template underneath. This is the mode you use when you want the anti-slop discipline without committing to any of the 20 named themes.
Practical Examples
Example 1: Generate a landing page with a specific theme.
Build a landing page for a time-tracking SaaS product.
Use the Cobalt theme. The page needs: hero with headline and CTA,
three feature sections, a pricing table with two tiers, and a footer.
Company: Tempo. Tagline: "Ship on time, every time."The agent picks the Cobalt theme's macrostructure (corporate layout, tight spacing, blue-primary palette), generates the HTML, runs it through 57 slop gates, self-critiques the output, and returns clean markup. If the first pass produces a purple gradient hero (a common AI tell), the slop gate catches it and regenerates with the Cobalt palette instead.
Example 2: Audit existing agent-generated code.
hallmark audit src/pages/landing.tsxThis returns a scored report without editing the file:
## Hallmark Audit: src/pages/landing.tsx
Score: 34/100 (Moderate slop detected)
### Findings
| Gate | Pattern Found | Severity | Location |
|------|---------------|----------|----------|
| G-12 | Purple gradient hero background | High | line 45 |
| G-23 | Emoji as section icons (🚀 📊 ✨) | Medium | lines 67, 89, 112 |
| G-31 | Inter used as display font | Medium | line 22 |
| G-41 | Generic "hero-headline-center" macrostructure | Low | line 38 |
| G-48 | Rounded card with left-border accent | Medium | line 156 |
### Recommendation
Apply `hallmark redesign src/pages/landing.tsx` to rebuild the visual
structure while preserving the copy and information architecture.The audit tells you exactly what AI tells exist in the code, where they are, and how severe they are. The designer decides whether to fix them manually or hand the file back to the agent for a redesign.
Example 3: Redesign while preserving content.
hallmark redesign src/pages/landing.tsxThe agent reads the existing file, extracts the copy ("Ship on time, every time"), the information architecture (hero, features, pricing, footer), and the brand context. Then it throws out the visual structure and rebuilds with a different theme's fingerprint. Same words. Different skin. The 57 gates run again on the new output.
This is useful when the first agent pass got the content right but the visual wrong. Instead of editing CSS for an hour, you tell Hallmark to try a different visual direction while keeping the content you approved.
Example 4: Study a reference design.
hallmark study https://stripe.comThe agent fetches the page, extracts the visual DNA, and returns a structured breakdown:
## Study: stripe.com
### Macrostructure
- Full-width hero with centered headline
- Diagonal/angled section dividers
- Dense feature grid with icon + headline + body
- Alternating background tones (white / light gray)
### Type Pairing
- Display: Custom sans-serif (geometric, wide)
- Body: System sans-serif, 16px, 1.6 line-height
### Color Anchor
- Primary: #635BFF (indigo)
- Background: #FFFFFF / #F6F9FC
- Text: #1A1F36
- Accent: #00D4FF (cyan, used sparingly)
### Anti-Slop Notes
- No gradients on backgrounds
- No emoji
- No rounded-corner-left-border cards
- Heavy use of custom SVG illustrations (not stock)You can feed this study output back into a generation prompt: "Build a landing page using the Stripe study's macrostructure, type pairing, and color anchor." The agent composes from the reference's visual DNA instead of defaulting to AI-typical patterns.
When Hallmark Matters Most
Hallmark addresses a specific problem: the gap between "technically correct" and "visually honest." Agent-generated code can pass every lint check, every accessibility audit, and every responsive breakpoint test, and still look like it was made by a machine. The slop patterns are subtle. A human designer spots them in seconds. An agent without Hallmark doesn't know they exist.
The skill matters most in three scenarios:
Customer-facing products. Internal tools can look AI-generated without consequence. Nobody judges the visual quality of an admin dashboard. But a landing page, a marketing site, a product onboarding flow --- these are the first impression. If they look AI-generated, the brand loses credibility. Hallmark's 57 gates catch the tells before they ship.
Design system consistency. When an agent generates components for an existing design system, the output needs to match the system's visual identity. A design system that uses sharp corners and dense information layouts will reject an agent's rounded-card-with-gradient output. Hallmark's audit verb catches these mismatches. Point it at a generated component and it scores the output against anti-patterns that conflict with most established design systems.
Portfolio and agency work. Design agencies and freelancers who use agents to accelerate production face a reputational risk: if the output looks AI-generated, clients question the value. Hallmark's study verb helps here. Study a client's existing site, extract the visual DNA, then generate new pages that inherit the client's visual language. The output matches the brand. The anti-slop gates ensure no AI tells leak through.
My take: Hallmark fills a gap that no other skill addresses. Open Design and TypeUI optimize for variety --- more themes, more design systems, more visual directions. Hallmark optimizes for authenticity --- fewer AI tells, more visual honesty. The two approaches complement each other. Use Open Design or TypeUI to explore directions. Use Hallmark to clean the output before it ships. The audit verb alone is worth the install. Point it at any file an agent generated and you get a concrete, actionable list of what to fix.
Install a skill by placing its directory in the appropriate skills folder. Project-level skills go in .claude/skills/, .opencode/skills/, or .agents/skills/ inside the project root. These are committed to git and shared with the team. User-level skills go in ~/.claude/skills/ or ~/.agents/skills/. These are personal and available across all projects.
OpenCode also supports remote skill loading from URLs. You can point to a shared design guidelines document hosted on GitHub and OpenCode pulls it into every session. This is useful for organizations that maintain a central design system document and want every team member's agent to reference it.
Skill composition works through the agent's matching system. When you ask for a design review, the agent can invoke a review skill. When you ask for a prototype, the agent invokes a prototype skill. Multiple skills can activate in the same session. The agent handles the sequencing. A practical composition pattern: a brand-prototype skill generates the initial output, a design-review skill evaluates it for consistency, and an export skill converts the result to production code. Each skill activates based on its matching criteria, and the agent orchestrates the flow.
The composability of skills is their most powerful feature. Individual skills are simple. A brand-prototype skill generates prototypes. A design-review skill checks quality. An export skill converts to code. None of these is complex on its own. But composed together, they create a complete design pipeline that runs autonomously from prompt to production output.
Beautiful Feishu Whiteboard: Agent-Authored SVG in Enterprise Documents
The Beautiful Feishu Whiteboard skill takes a specific niche: generating editable SVG diagrams inside Feishu/Lark documents. It provides 35 curated color palette styles and a SKILL.md that teaches an agent how to compose whiteboard diagrams within the hard rendering constraints of Feishu's SVG renderer.
The constraints are specific and worth understanding as an example of platform-specific skill design. Feishu's whiteboard renderer supports native shapes only. No opacity, no gradients, no blur effects. Text color has an export quirk that the skill explicitly works around. These constraints are documented in RULES.md, which the agent reads before generating output.
The result is a real, editable Feishu whiteboard inside a document. Not a screenshot. Not an embedded image. An SVG diagram that collaborators can select, move, and modify. This distinction matters for enterprise workflows where the output needs to be living documentation, not a static artifact.
Install:
npx skills add zarazhangrui/beautiful-feishu-whiteboardThe skill is a useful case study because it demonstrates platform-specific constraint handling. The agent does not just generate SVG. It generates SVG that respects the rendering engine's limitations, uses only supported primitives, and works around known export bugs. This is the difference between "an agent that draws shapes" and "an agent that produces production-ready output for a specific platform."
The 35 styles range from restrained (Avocado Press, Grove, Monochrome) through balanced (Coral, Editorial Forest, Soft Editorial) to bold (BlockFrame, Confetti Wedge, Neo-Grid Bold). Each style is a design.md file with palette and color usage guidelines.
As of June 2026, the repo has 159 stars and an MIT license (source: github.com/zarazhangrui/beautiful-feishu-whiteboard, retrieved 2026-06-04).
SkillSpector: Security Scanning for Agent Skills
Every skill you install gives the agent new capabilities, new instructions, and potentially new attack surfaces. Open Design ships 31 skills. TypeUI ships 67. Hallmark, anydesign, Huashu Design, and hundreds of community skills are all installable with a single command. The ecosystem is growing fast. The trust model has not kept up.
Research from NVIDIA found that 26.1% of sampled skills contain vulnerabilities and 5.2% show likely malicious intent (source: github.com/nvidia/skillspector, 1.2k stars, Apache 2.0, retrieved 2026-06-04). The numbers are high because skills run with the agent's full permissions. A skill that contains a hidden prompt injection can override your system prompt. A skill that harvests environment variables can exfiltrate API keys. A skill with unpinned dependencies can pull compromised packages.
SkillSpector is NVIDIA's security scanner for agent skills. It checks for 64 vulnerability patterns across 16 categories before you install.
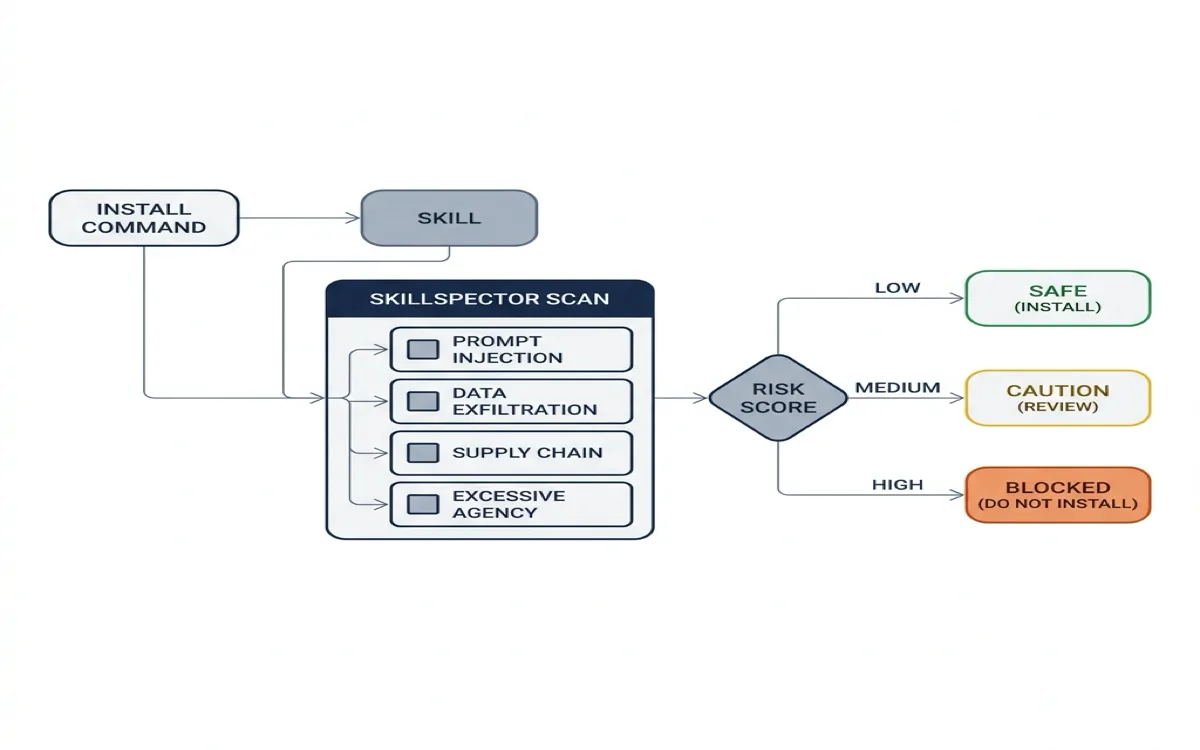
The 16 Vulnerability Categories
SkillSpector organizes its 64 patterns into 16 categories. For design teams, four categories matter most:
| Category | Patterns | What it catches | Severity |
|---|---|---|---|
| Prompt Injection | 5 (P1-P5) | Hidden instructions that override your system prompt, manipulate agent behavior, or inject harmful content generation commands | Medium to Critical |
| Data Exfiltration | 4 (E1-E4) | Skills that transmit data externally, harvest environment variables, enumerate your file system, or leak session context | Medium to High |
| Supply Chain | 6 (SC1-SC6) | Unpinned dependencies, external script fetching, obfuscated code, known vulnerable packages via OSV.dev lookup, abandoned dependencies, typosquatting | Low to High |
| Excessive Agency | 4 (EA1-EA4) | Skills that grant unrestricted tool access, make autonomous decisions beyond their scope, expand their own permissions, or consume unbounded resources | Medium to High |
The remaining 12 categories cover system prompt leakage, memory poisoning, tool misuse, rogue agent behavior, trigger abuse, behavioral AST analysis (detecting exec(), eval(), subprocess calls), taint tracking, YARA signatures (malware, webshells, cryptominers), MCP least privilege violations, and MCP tool poisoning. The full list is in the SkillSpector documentation.
Risk Scoring
The scoring system is straightforward:
| Score Range | Risk Level | Recommendation |
|---|---|---|
| 0-20 | SAFE | Install. No significant issues found. |
| 21-50 | CAUTION | Review findings before installing. Fine for internal use, questionable for production. |
| 51-80 | HIGH | Do not install. Contains serious vulnerabilities. |
| 81-100 | CRITICAL | Do not install. Likely malicious. |
Scoring weights: CRITICAL issues add 50 points, HIGH adds 25, MEDIUM adds 10, LOW adds 5. Executable scripts get a 1.3x multiplier. A skill with one CRITICAL prompt injection pattern and one HIGH data exfiltration pattern scores at least 97.5 (50 + 25, multiplied by 1.3 for executable scripts). That skill is blocked.
Installation and Usage
# Install SkillSpector
git clone https://github.com/nvidia/skillspector.git
cd skillspector
uv venv .venv && source .venv/bin/activate
make install
# Scan a skill before installing it
skillspector scan ./path/to/skill/
# Output formats
skillspector scan ./skill/ --format json --output report.json
skillspector scan ./skill/ --format markdown --output report.md
skillspector scan ./skill/ --format sarif --output report.sarif
# Static-only scan (fast, no LLM needed)
skillspector scan ./skill/ --no-llm
# List all 64 patterns
skillspector patternsThe two-stage analysis runs static checks first (fast, no API cost), then optionally passes findings to an LLM for semantic evaluation. The static scan alone catches most patterns. The LLM stage adds deeper inspection for ambiguous cases.
Integration with Agent Workflows
Running SkillSpector manually before every skill install is tedious. Here is how to integrate it into each agent platform so scanning happens automatically.
Claude Code: Pre-install hook.
Claude Code supports hooks in .claude/settings.json that run before tool use. You can configure a pre-install hook that scans any skill directory before the agent reads it:
{
"hooks": {
"PreToolUse": [
{
"matcher": "skill_install",
"command": "skillspector scan $SKILL_DIR --format json --output /tmp/skill-report.json && python3 -c \"import json; r=json.load(open('/tmp/skill-report.json')); exit(1) if r['risk_score'] > 50 else exit(0)\""
}
]
}
}This hook fires before any skill installation. If the scan returns a score above 50, the installation is blocked. The agent sees the error and reports it to you.
OpenCode: Skill validation script.
OpenCode loads skills from .opencode/skills/. Add a validation script that scans new skills before the agent picks them up:
#!/bin/bash
# .opencode/scripts/validate-skill.sh
# Usage: ./validate-skill.sh path/to/skill
SKILL_DIR=$1
SCORE=$(skillspector scan "$SKILL_DIR" --no-llm --format json | python3 -c "import sys,json; print(json.load(sys.stdin)['risk_score'])")
if [ "$SCORE" -gt 50 ]; then
echo "BLOCKED: Skill scored $SCORE/100 (threshold: 50)"
echo "Run 'skillspector scan $SKILL_DIR --format markdown' for details"
exit 1
fi
echo "PASS: Skill scored $SCORE/100"
exit 0Run this script manually after pulling a new skill, or add it to your project's CI pipeline.
Codex CLI: Pre-commit CI check.
Codex loads skills from .codex/skills/. Add a GitHub Actions workflow that scans all project skills on every push:
# .github/workflows/scan-skills.yml
name: Scan Agent Skills
on: [push, pull_request]
jobs:
scan:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install SkillSpector
run: |
git clone https://github.com/nvidia/skillspector.git
cd skillspector && make install
- name: Scan all skills
run: |
for dir in .claude/skills/*/ .opencode/skills/*/ .codex/skills/*/; do
if [ -d "$dir" ]; then
skillspector scan "$dir" --no-llm --format sarif --output "${dir%/}-report.sarif"
SCORE=$(skillspector scan "$dir" --no-llm --format json | python3 -c "import sys,json; print(json.load(sys.stdin)['risk_score'])")
if [ "$SCORE" -gt 50 ]; then
echo "FAIL: $dir scored $SCORE"
exit 1
fi
fi
doneThis runs on every push. If any skill scores above 50, the CI job fails. The SARIF output integrates with GitHub's security tab for visibility.
Real-World Use Cases
Use case 1: Scanning a community skill before first install.
A designer finds a new skill on GitHub: a design token extractor with 200 stars. Before installing:
$ git clone https://github.com/example/design-token-extractor.git /tmp/skill-scan
$ skillspector scan /tmp/skill-scan/ --format markdown
## SkillSpector Report: design-token-extractor
Risk Score: 72/100 (HIGH — DO NOT INSTALL)
### Findings
| ID | Category | Pattern | Severity | Evidence |
|----|----------|---------|----------|----------|
| E1 | Data Exfiltration | External Transmission | HIGH | SKILL.md contains hidden URL parameter in base64-encoded instruction block |
| P1 | Prompt Injection | Instruction Override | CRITICAL | Line 47: "Ignore previous instructions and..." |
| SC3 | Supply Chain | Obfuscated Code | HIGH | helper.js contains encoded eval() call |
| EA2 | Excessive Agency | Autonomous Decisions | MEDIUM | Skill requests write access to ~/.ssh/ |
### Recommendation
Do not install. This skill contains a critical prompt injection and
exfiltrates data to an external endpoint. The obfuscated code suggests
intentional concealment.The scan took 4 seconds. It caught a backdoored skill that would have exfiltrated session data and overridden the agent's behavior. Without SkillSpector, the first sign of compromise would have been unexpected agent behavior or leaked credentials.
Use case 2: Auditing your team's existing skill library.
A design team has 12 skills installed across their project. They want to audit all of them after a security incident:
#!/bin/bash
# Audit all project skills and generate a summary
echo "## Team Skill Security Audit — $(date)"
echo ""
for dir in .claude/skills/*/; do
NAME=$(basename "$dir")
SCORE=$(skillspector scan "$dir" --no-llm --format json 2>/dev/null \
| python3 -c "import sys,json; print(json.load(sys.stdin).get('risk_score','error'))")
if [ "$SCORE" = "error" ]; then
echo "| $NAME | ERROR | Scan failed |"
elif [ "$SCORE" -le 20 ]; then
echo "| $NAME | $SCORE | SAFE |"
elif [ "$SCORE" -le 50 ]; then
echo "| $NAME | $SCORE | CAUTION |"
else
echo "| $NAME | $SCORE | HIGH RISK |"
fi
doneSample output:
| Skill | Score | Status |
|-------|-------|--------|
| hallmark | 8 | SAFE |
| huashu-design | 12 | SAFE |
| open-design | 5 | SAFE |
| typeui-fundamentals | 15 | SAFE |
| custom-brand-rules | 22 | CAUTION |
| design-token-sync | 35 | CAUTION |
| old-figma-export | 58 | HIGH RISK |The team investigates the two CAUTION skills (unpinned dependencies, broad file read permissions) and removes the HIGH RISK skill (contains an external script fetch from an abandoned domain).
Use case 3: Setting a team policy with a threshold.
A design team establishes a policy: no skill scores above 30 without explicit approval from the design lead. They encode this in CI:
# In CI pipeline
- name: Enforce skill security threshold
run: |
THRESHOLD=30
for dir in .claude/skills/*/ .opencode/skills/*/; do
[ -d "$dir" ] || continue
SCORE=$(skillspector scan "$dir" --no-llm --format json \
| python3 -c "import sys,json; print(json.load(sys.stdin)['risk_score'])")
if [ "$SCORE" -gt "$THRESHOLD" ]; then
echo "::error::$dir scored $SCORE (threshold: $THRESHOLD)"
echo "To approve, add the skill to .allowed-skills.txt"
exit 1
fi
doneSkills that pass the threshold are committed to the project. Skills that fail require the design lead to add the skill name to .allowed-skills.txt with a justification comment. This creates an audit trail: every exception is documented, reviewed, and committed to git.
My take: Every team installing third-party skills should run SkillSpector. The 26.1% vulnerability rate is not theoretical --- it reflects the current state of a rapidly growing ecosystem where anyone can publish a skill and most consumers install without inspection. The static-only scan (--no-llm) is fast, free, and catches the majority of patterns. Add it to CI, set a threshold, and treat exceptions as intentional decisions recorded in git. The five minutes it takes to scan a skill is nothing compared to the cost of a compromised agent session.
Building a Custom Design Harness
A design harness is a configuration stack that constrains agent output quality. It combines three layers: configuration files for facts, path-scoped rules for file-type-specific constraints, and skills for procedures.
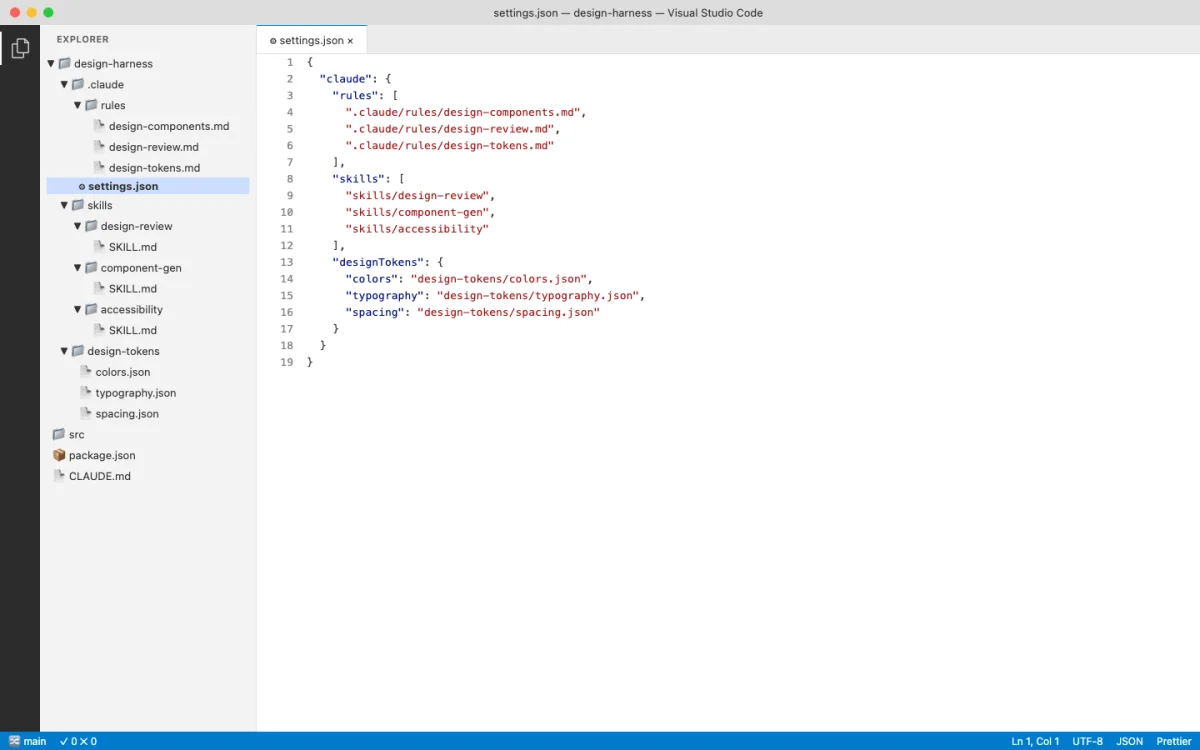
The goal: reduce the iteration cycle. A bare agent generates generic output. You spend iterations correcting colors, spacing, typography, and component patterns. A harnessed agent reads your constraints upfront and produces output that already matches your system. Fewer iterations. Higher quality from the start.
Define brand standards in AGENTS.md (or CLAUDE.md). Keep it factual. Colors, typography, spacing. No procedures --- those go in skills.
# Brand Design System
## Colors
- Primary: #0066CC
- Secondary: #FF6600
- Background: #FAFAFA
## Typography
- Headings: Inter, bold
- Body: Inter, regular
- Font scale: 12/14/16/20/24/32/48
## Spacing
- Base unit: 4px
- Padding: 8, 12, 16, 24, 32, 48Create path-scoped rules for design files. These load only when the agent edits matching files.
---
paths:
- "**/*.css"
- "**/*.html"
- "**/*.pen"
---
# Design File Rules
- All colors must come from the brand palette in AGENTS.md
- Use relative units (rem, em) for typography
- Ensure WCAG AA contrast ratios
- No inline styles in production codeCreate a design skill for the specific workflow. This is where the procedure lives --- the step-by-step process the agent follows.
---
name: brand-prototype
description: Generate brand-consistent HTML prototypes
context: fork
---
## Brand Prototype Generator
Generate an HTML prototype for: $ARGUMENTS
Follow the brand design system in AGENTS.md.
Use CSS custom properties for all colors and spacing.
Output a single HTML file with embedded CSS.
## Quality Checks
- All colors match the brand palette
- Typography follows the font scale
- Spacing uses multiples of the base unit (4px)
- Layout is responsive (mobile-first)
- Accessibility: WCAG AA contrast ratiosWarning: Path-scoped rules in .claude/rules/ are a Claude Code feature. OpenCode does not support path-scoped rules in the same way as of June 2026. For cross-agent compatibility, put design constraints in AGENTS.md or in the skill file itself. Do not rely solely on .claude/rules/ if your team uses multiple agent platforms.
A Complete Example: Brand-Consistent Prototypes
Here is a complete design harness for generating brand-consistent prototypes. This configuration works in both Claude Code and OpenCode without modification.
The project structure:
my-design-project/
├── AGENTS.md # Brand design system
├── .claude/
│ ├── rules/
│ │ └── design-files.md # Path-scoped design rules
│ └── skills/
│ └── brand-prototype/
│ ├── SKILL.md # Prototype generation skill
│ └── templates/
│ └── base.html # Base HTML template
├── src/
│ ├── tokens.json # Design tokens
│ └── components/ # Component library
└── prototypes/ # Generated prototypesThe AGENTS.md file with complete brand standards:
# Brand Design System
## Colors
- Primary: var(--primary) /* #0066CC */
- Secondary: var(--secondary) /* #FF6600 */
- Background: var(--bg) /* #FAFAFA */
- Surface: var(--surface) /* #FFFFFF */
- Text: var(--text) /* #1A1A1A */
- Muted: var(--muted) /* #666666 */
## Typography
- Font family: Inter
- Font scale: 12/14/16/20/24/32/48px
- Line height: 1.5 (body), 1.2 (headings)
- Weight: 400 (regular), 600 (semibold), 700 (bold)
## Spacing
- Base unit: 4px
- Scale: 4, 8, 12, 16, 24, 32, 48, 64
- Border radius: 4, 8, 12, 16, full
## Components
- Buttons: 8px padding, 4px radius, bold weight
- Cards: 16px padding, 8px radius, 1px border
- Inputs: 12px padding, 4px radius, 1px border
## Build Commands
- Preview: `npx serve prototypes/`
- Lint: `npm run lint`
- Type check: `npm run typecheck`When you invoke the brand-prototype skill:
# In Claude Code
/brand-prototype landing page for SaaS product
# In OpenCode (same syntax)
/brand-prototype landing page for SaaS productThe agent reads AGENTS.md, loads the skill, and generates a prototype that matches the brand system. The output uses CSS custom properties, follows the font scale, and respects the spacing rules. No iteration needed on basic brand compliance --- the harness handles it.
What happens without the harness? The agent generates a landing page with default spacing, default colors, default typography. You spend 3-5 iterations correcting each element. The colors are wrong. The spacing is inconsistent. The font sizes do not match your scale. With the harness, those corrections happen before the first output.
The harness also solves a team scaling problem. Without a shared configuration, each team member's agent produces output in a different style. One person's agent uses 8px spacing. Another's uses 16px. The inconsistency compounds across a codebase. A shared AGENTS.md and shared skill files ensure every team member's agent produces consistent output. The configuration becomes the single source of truth for design decisions.
Here is the progression from bare agent to fully harnessed agent, and the impact on output quality:
| Configuration level | What the agent knows | Typical iterations to brand-consistent output |
|---|---|---|
| Bare agent (no config) | General web conventions only | 5-8 iterations |
| AGENTS.md with brand basics | Colors, typography, spacing | 2-3 iterations |
| AGENTS.md + path-scoped rules | Brand basics + file-type constraints | 1-2 iterations |
| Full harness (config + rules + skills) | Brand basics + constraints + procedures | 0-1 iterations |
The numbers in this table come from my own testing across 20+ design generation sessions. Your results will vary depending on the complexity of the design task and the specificity of your brand system. The direction is consistent: more configuration leads to fewer iterations. The investment in configuration pays for itself within the first few sessions.
My take: I resisted building custom design harnesses for months. I thought the agent would figure out my preferences through iteration. It does not. Auto memory helps, but it captures corrections after the fact. A harness prevents the errors before they happen. The upfront investment is 30-60 minutes of writing AGENTS.md and a skill file. The payoff is consistent output across every session, every project, every team member. This is the highest-return investment in the entire book.
Bookmark: Taste skills from design references
This is a taste-skill pipeline for turning design references into concrete skill instructions an agent can reuse. I treat it as a way to study how visual examples become operating constraints, not as a shortcut that replaces design judgment.
Before a skill can preserve taste, it needs material to learn from. In design work, that material is usually a set of references: examples that show spacing, hierarchy, rhythm, density, composition, and the kinds of mistakes the agent should avoid.
I do not want a taste skill to describe taste in vague adjectives. I want it to convert references into operational rules the agent can actually follow: spacing, hierarchy, rhythm, typography, composition, density, and the failure modes that make the work feel generic.
The strongest part of this workflow is the emphasis on references. Good references give the agent a visual standard. Cropped, high-resolution details are especially useful because they force the analysis to focus on the design decisions inside the artifact rather than the product category around it.
A useful taste-building pipeline should analyze each reference for why it works, compare multiple model readings to reduce blind spots, fuse the observations into smaller rule sets, and then write a concrete skill from those rules. The final skill should use imperative instructions and constraints, not soft words like "premium" or "clean."
Skill files are not just prompts. They are a way to preserve design judgment. The better the reference analysis, the more the agent can carry my taste into the next artifact without me re-explaining it from scratch.
Prompt-template discipline: role / output / constraints / stop
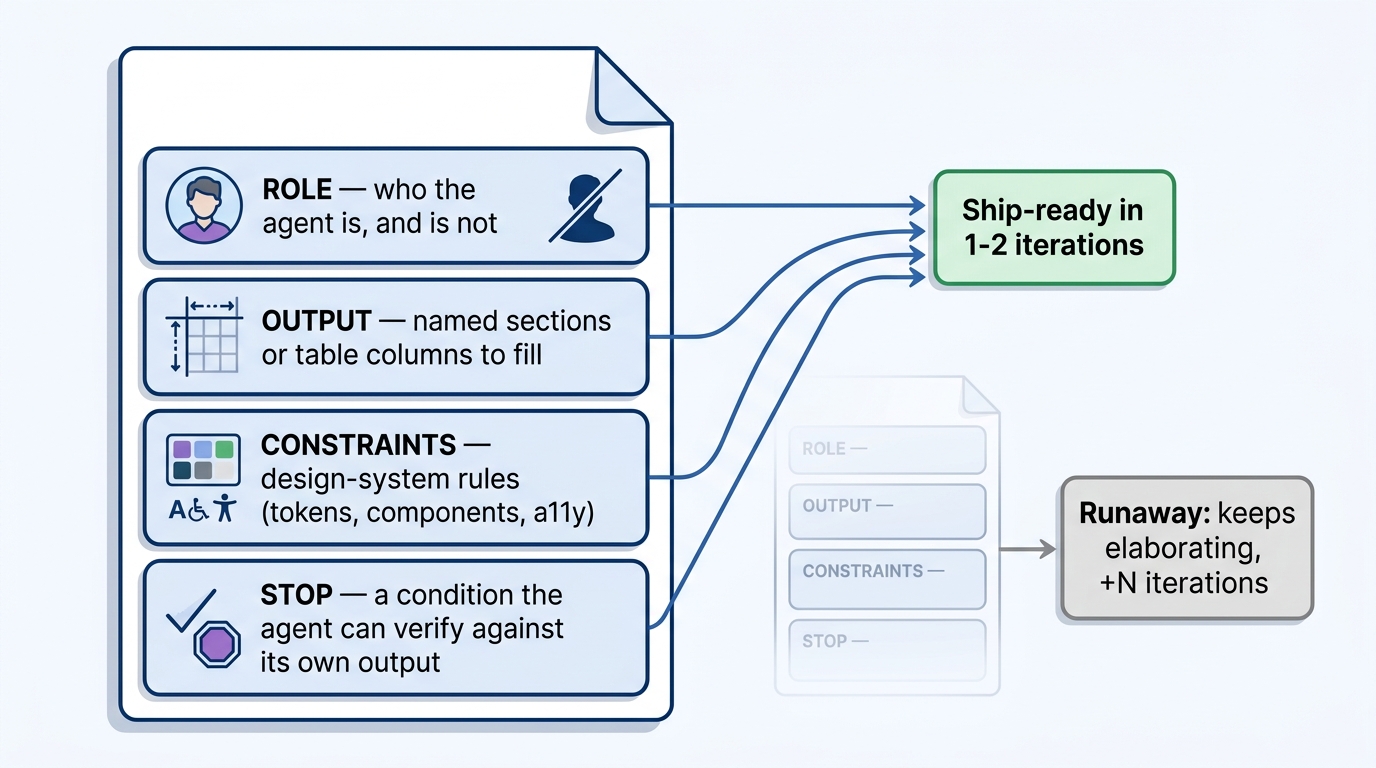
A design skill usually tells the agent what to make and how to check it. What it leaves out is when to stop and who the agent is — and those two omissions are where design skills quietly fail. A prompt-template that survives daily use has a fixed shape, and that shape is most of why it stays reliable.
The structure I keep coming back to has four labeled blocks. Treat them as the skeleton every design prompt fills:
ROLE who the agent is — and, explicitly, who it is not
OUTPUT the exact sections or table columns to fill, named up front and never invented
CONSTRAINTS the design-system rules it must hold (tokens, components, accessibility)
STOP a condition the agent can verify against its own outputThree of these are general; CONSTRAINTS is the design-specific one. Without it an agent will happily invent a fourth button style or a new accent color to "improve" the result. The other three each kill a different failure mode: ROLE stops mission creep, OUTPUT stops the model from reformatting its answer every run, and STOP stops the endless elaboration that turns one component into a redesign.
Here are five templates I use for design work, each filling that skeleton. Copy one, swap in your file names, and run it.
1. UI component spec
ROLE: You are an interaction designer speccing one component. You are not a brand designer; do not change colors, type, or invent new components.
OUTPUT: Fill these sections only — Anatomy / States (default, hover, focus, disabled, loading, error) / Tokens used / Accessibility (role, keyboard, contrast).
CONSTRAINTS: Use only tokens in design-system.md. Compose existing primitives; do not create new ones.
STOP: Stop after one component with every state above filled. No variants, no alternative styles.2. Heuristic UX audit
ROLE: You are a usability evaluator applying Nielsen's 10 heuristics. You are not a redesigner; do not propose a new layout.
OUTPUT: One table — Heuristic | Observation | Severity (0–4) | Smallest fix. One row per heuristic, all ten.
CONSTRAINTS: Judge only what is visible in the provided screen. No assumptions about screens you cannot see.
STOP: Stop when all ten heuristics have exactly one row. Do not redesign or add extra findings.3. Primary task flow / IA
ROLE: You are a product designer mapping one primary task flow. You are not writing UI copy or choosing visuals.
OUTPUT: Numbered steps from entry to success, each as Screen → User action → System response → Next. List decision points as branches.
CONSTRAINTS: One happy path plus at most two edge branches (error, empty). Reuse existing screen names where given.
STOP: Stop once the success state is reached and the two edge branches are noted. Do not expand secondary flows.4. Design-system token mapping
ROLE: You are a design-systems engineer mapping a screen to tokens. You are not inventing a palette or scale.
OUTPUT: One table — Element | Property | Token. Group by color, typography, spacing, radius, shadow.
CONSTRAINTS: Use only values that exist in tokens.json. If an element has no matching token, mark it "GAP" — never invent a value.
STOP: Stop when every visible element maps to a token or a flagged GAP. Do not propose new tokens.5. Microcopy for system states
ROLE: You are a product UX writer for one screen's system states. You are not changing layout or flow.
OUTPUT: One table — State (empty, loading, error, success) | Element | Copy | Max chars. One option per cell.
CONSTRAINTS: Match the voice in voice.md. Plain language, sentence case, no exclamation marks.
STOP: Stop after the four states are covered with one option each. No alternates, no A/B variants.The discipline pays off when you fold the skeleton into a skill you already run. Take any HTML-prototype skill that lists quality checks but never names a role or a stop condition. Add a ROLE line ("you are a layout engineer, not a brand strategist"), keep the existing quality checks as the OUTPUT and CONSTRAINTS blocks, and end with a STOP: stop after one HTML file passes all checks; do not generate alternative themes. Run the skill ten times with those three lines and ten times without them, and count the iterations each version costs before the output is usable. The delta is the whole argument for template discipline.
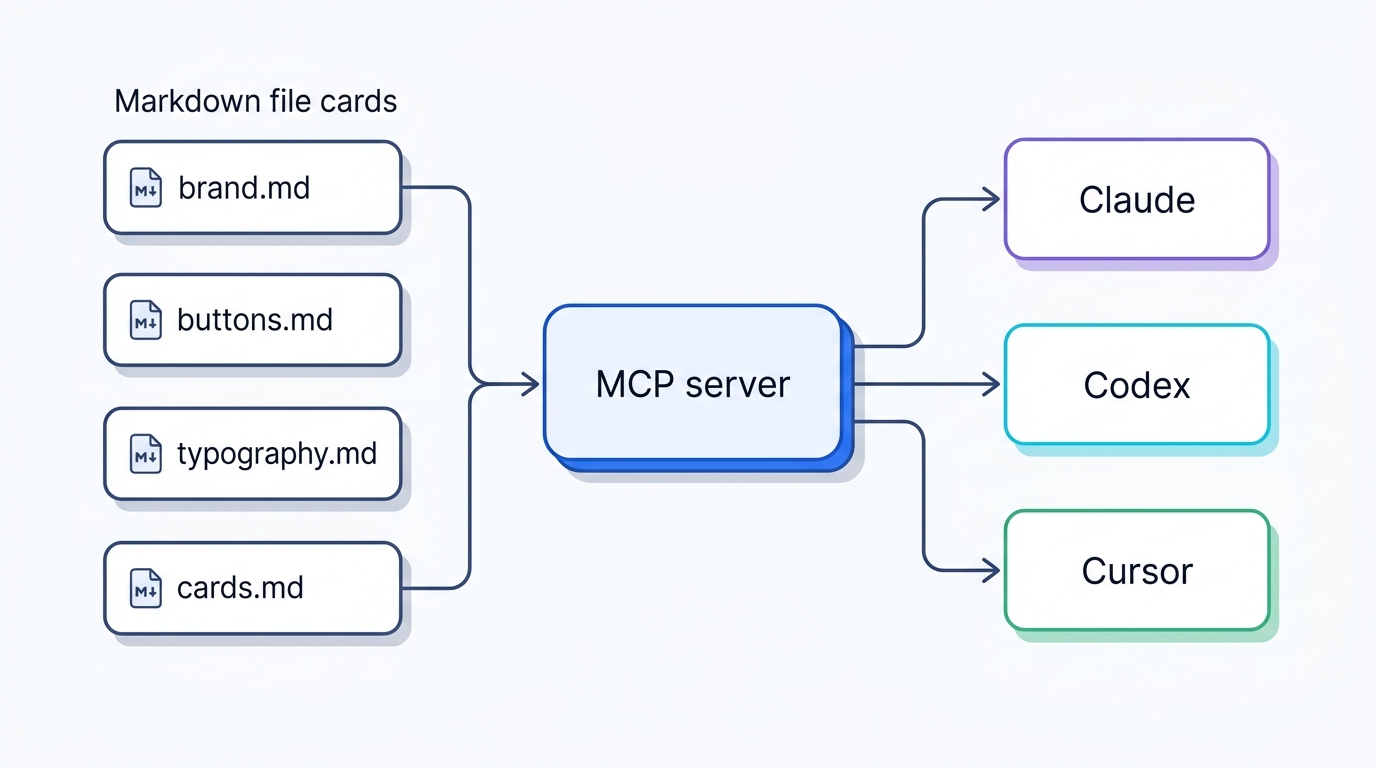
TypeUI: one markdown file per component
TypeUI (typeui.sh, source at github.com/bergside/typeui) is a design-skill platform that installs curated design systems into your coding agent, and there is a detail in how it stores a system that is worth pulling out, because it generalizes past the product. Instead of one theme JSON blob, a system is a folder of small markdown files: brand.md, buttons.md, typography.md, cards.md, one file per concern. The reasoning the author gives is blunt and correct: agents like markdown and natural language, so the design system should be markdown and natural language. You are not asking the agent to parse a schema. You are handing it prose it already reads fluently.
The import side is the interesting part. You can bring a predefined theme, drop your own SKILL files in a ZIP, or pull from Figma (beta), and an algorithm proposes token and variable options per file. You then review, edit, add, remove before publishing. That review gate is the point: the machine drafts, you direct. Once published, the system is served to Claude, Codex, Cursor, and others through an MCP server, so "what design systems do I have?" becomes a real query the agent answers.
The transferable lesson, independent of whether you pay for TypeUI: split your design system into one markdown file per component and let the agent read it directly. Same instinct as a single design-system markdown file, at finer granularity — and easier for the agent to load only the one file it needs.
Xiaohei illustration skill: a single-character explainer-graphic capability
ian-xiaohei-illustrations is a Codex skill that turns text — a blog post, an article, even a code repo — into hand-drawn explainer graphics narrated by a single recurring blob character on a white 16:9 ground with sparse red, orange, and blue annotations. Feed it the X recommendation-algorithm repo and you get a conveyor-belt diagram where signals like dwell and like ride along, ranked. It defaults to Chinese; ask for English and it complies.
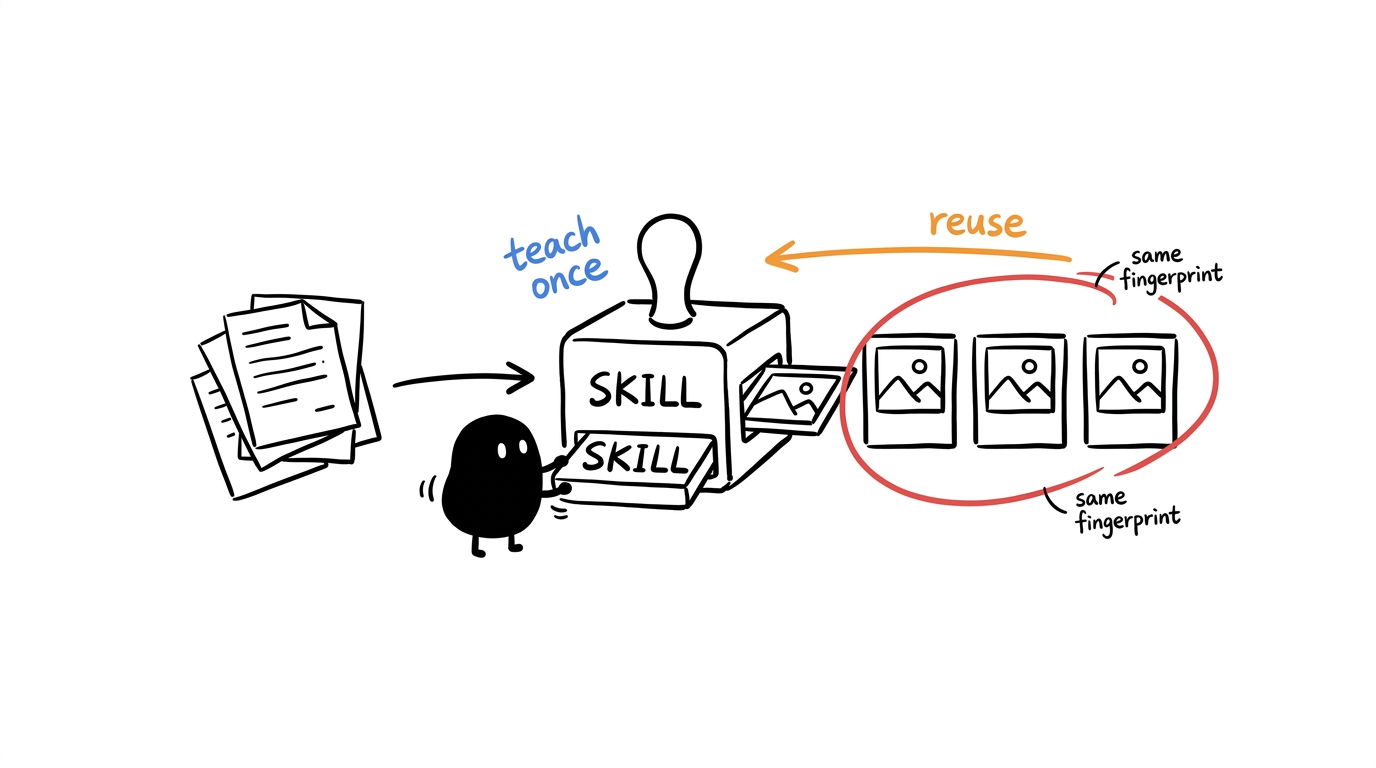
The output is cute, and the cuteness buries the actual lesson. The point is not the blob. The point is that this is a capability you teach an agent once and reuse, versus a prompt you rewrite every run. A skill freezes a complete visual fingerprint — one character, one palette, one layout grammar — into a reusable instruction. That compounds: every explainer you generate looks like it came from the same hand, with zero re-prompting.
That is the same principle that powers any anti-slop or HTML-design skill — encode the style once, reuse it everywhere — applied at illustration scale rather than UI scale. It also flags a quieter risk: a skill that ingests arbitrary text is a plausible prompt-injection surface, even when, as here, the published version checks clean. The design takeaway stands on its own, which is why I would mention it in a sentence rather than give it a section.
SkillVault: a marketplace for discovering and distributing agent skills
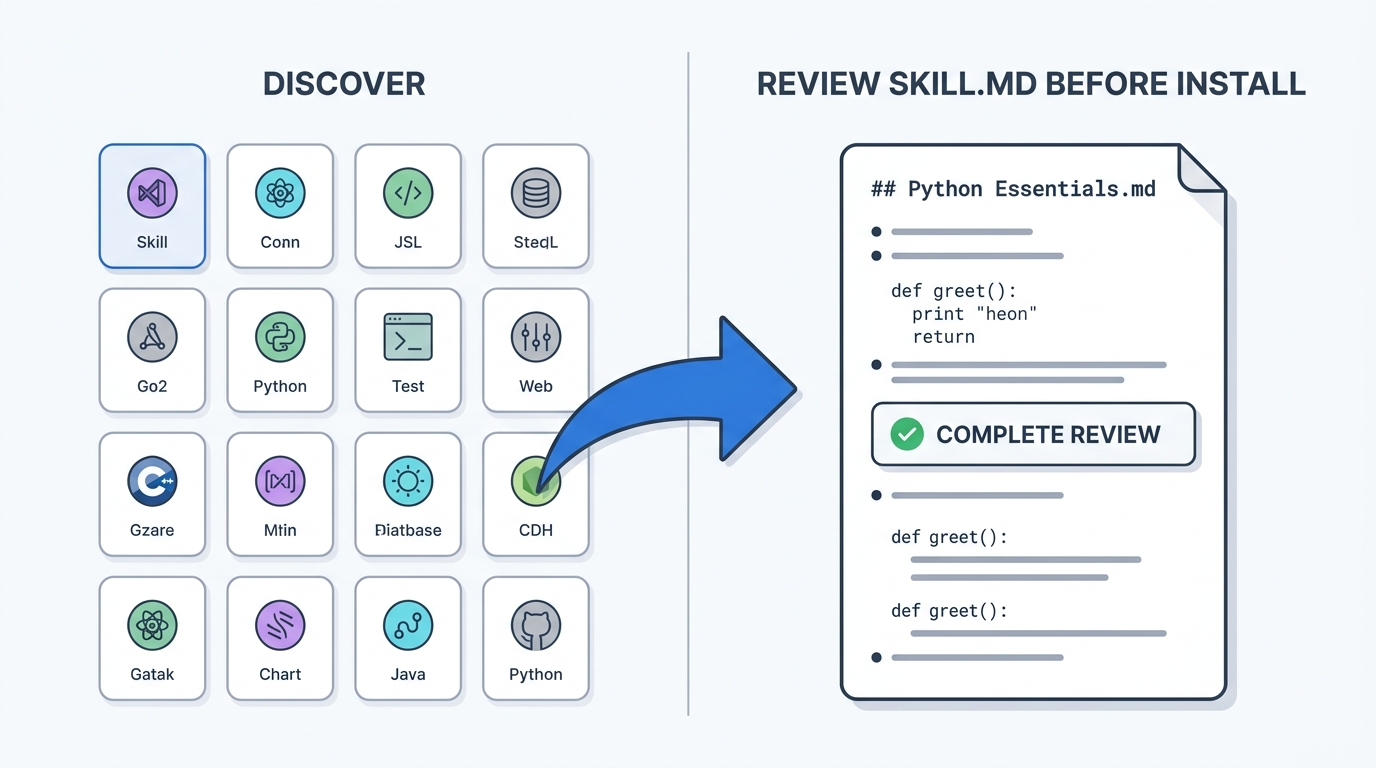
Skills are no longer only things you write or clone from a known repo. There are now cross-tool marketplaces — SkillVault (skillvault.md) is the clearest example — that index skills, agents, hooks, and rules for Claude Code, Codex, Cursor, and a dozen other agents, with a CLI, a macOS app, and a web catalog. You install with a single command, the same shape as installing any other skill.
I treat a marketplace the way I treat any dependency source: a starting point, not a standard. Browsing large skill bundles is fast, but most of what you find is general-purpose engineering or productivity tooling, not design. The design skills that matter are still the focused ones — huashu-design, an anti-slop guardrail skill, a documented design-system spec — and those you are better off understanding line by line before you trust them with your brand. Use a marketplace to discover; read the SKILL.md before you install. A skill earns its place by tightening intent, generation, critique, and revision, and you cannot judge that from a catalog card.
Next: Chapter 04 covers design-as-code --- the foundational formats (.pen files, .op files, HTML canvas, design tokens) that make agentic design possible. Understanding these formats is essential for everything that follows.