MCP: The Universal Design Tool Connector
MCP is a standardized protocol that lets AI agents talk to external tools. Think of it as an authenticated API that an LLM can call during a conversation. Instead of copying design specs between tools by hand, the agent reads from one MCP server and writes to another. All in a single session.
MCP servers expose three things: tools (functions the agent can call), resources (data the agent can read), and prompts (guided workflows). For design work, tools are what matter most. A tool like get_jsx on the Paper MCP server is the difference between manually translating a design and having the agent do it in seconds.
Two transport types exist. HTTP (remote) connects to a URL like https://mcp.figma.com/mcp. stdio (local) spawns a process on your machine. Figma uses HTTP. Paper uses HTTP too, but the server runs locally inside the Paper Desktop app at http://127.0.0.1:29979/mcp. The transport type matters for configuration, which I cover next.
As of May 2026, MCP is supported by every major agent platform: Claude Code, Codex CLI, Cursor, VS Code Copilot, OpenCode, Windsurf, Gemini CLI, Warp, Kiro, Factory, Firebender, Replit, Amazon Q, and Android Studio. The ecosystem is mature enough that MCP support is table stakes for any agent tool.
Configuring MCP Servers in Each Agent Platform
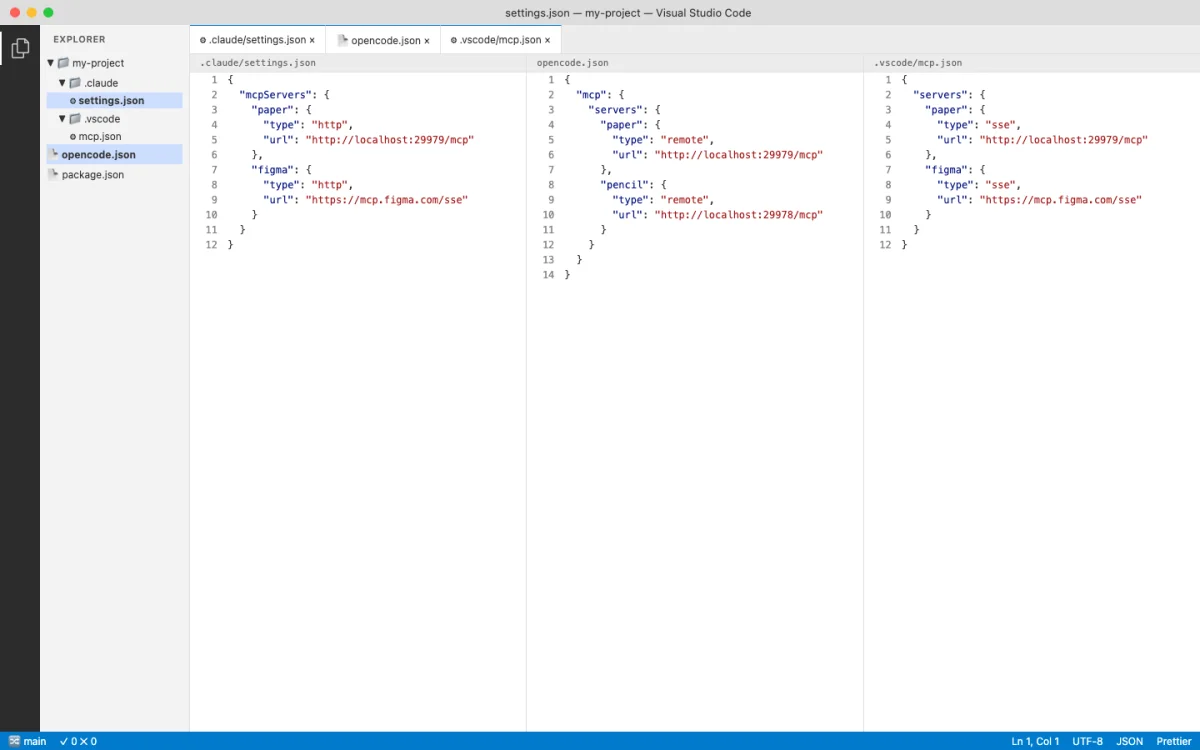
Every agent platform has its own MCP configuration syntax. Some use CLI commands. Others use JSON config files. A few support both. Here is the complete reference for the three agents this book focuses on, plus VS Code and Cursor for teams using those editors.
Claude Code
Claude Code supports two approaches: the mcp add CLI command and the plugin system. Plugins are preferred because they include skill files that teach the agent how to use the MCP tools effectively.
# Plugin approach (preferred for Figma)
$ claude plugin install figma@claude-plugins-official
# Plugin approach for Paper
$ claude plugin install paper-desktop@paper
# Manual remote server (Figma)
$ claude mcp add --scope user --transport http figma https://mcp.figma.com/mcp
# Manual local server (Paper via stdio bridge)
$ claude mcp add --transport stdio paper -- npx mcp-remote http://127.0.0.1:29979/mcp
# Verify: type /mcp in Claude Code
# You should see figma and paper listed
# Authenticate when promptedThe --scope user flag makes the MCP server available across all projects. Without it, the server is scoped to the current project only. For design tools you use daily, user-scoped is the right default.
Codex CLI
Codex uses a simpler configuration model. The mcp add command takes a name and URL. For tools that need plugins (like Figma), use the app settings UI.
# CLI: add Figma remote server
$ codex mcp add figma --url https://mcp.figma.com/mcp
# App: Settings > Plugins > + Figma > Install > Authenticate
# App: Settings > MCP Servers > Streamable HTTP
# Name: paper, URL: http://127.0.0.1:29979/mcpOpenCode
OpenCode configures MCP servers in opencode.json. The configuration is declarative JSON, which makes it versionable and shareable across a team.
// opencode.json
{
"mcp": {
"paper": {
"type": "remote",
"url": "http://127.0.0.1:29979/mcp",
"enabled": true
},
"figma": {
"type": "remote",
"url": "https://mcp.figma.com/mcp",
"enabled": true
}
}
}VS Code and Cursor
VS Code and Cursor both use JSON config for MCP servers, placed in .vscode/mcp.json at the project root. Cursor additionally supports a plugin deep-link format.
// .vscode/mcp.json
{
"servers": {
"figma": {
"url": "https://mcp.figma.com/mcp",
"type": "http"
},
"paper": {
"type": "http",
"url": "http://127.0.0.1:29979/mcp"
}
}
}For Cursor, the plugin approach is cleaner:
# Cursor plugins
/add-plugin figma
/add-plugin paper-desktop
# Cursor deep link for Figma (one-click setup)
cursor://anysphere.cursor-deeplink/mcp/install?name=Figma&config=...The following table summarizes the configuration approach for each agent platform.
| Platform | Config Method | Remote Servers | Local Servers | Plugin Support |
|---|---|---|---|---|
| Claude Code | CLI + opencode.json |
mcp add --transport http |
mcp add --transport stdio |
Yes (claude plugin) |
| Codex CLI | CLI + App Settings | mcp add --url |
App Settings only | Yes (Skills) |
| OpenCode | opencode.json |
"type": "remote" |
"type": "local" |
Yes (Skills) |
| VS Code | .vscode/mcp.json |
"type": "http" |
"type": "stdio" |
Yes (Extensions) |
| Cursor | .vscode/mcp.json + plugins |
"type": "http" |
"type": "stdio" |
Yes (/add-plugin) |
My take: Claude Code's plugin system is the most mature MCP configuration experience as of May 2026. The plugin includes both the server connection and the skill file that teaches the agent how to use the tools. With Codex and OpenCode, you get the connection but need to write your own skill context. This gap will close, but right now Claude Code has the edge for MCP-heavy workflows.
Figma MCP Server: Reading Designs Programmatically
Figma offers two MCP server types: Remote at https://mcp.figma.com/mcp (available to all plans) and Desktop (runs inside the Figma desktop app, available on Dev or Full seats for paid plans). The remote server is the one to use. It supports write-to-canvas, code-to-canvas, and diagram generation. The desktop server is limited to read operations for most users.
Authentication is OAuth-based. When you first connect, a browser window opens for the Figma sign-in flow. After that, the token is cached. No API keys to manage.
Figma's MCP server exposes 18 tools. Here is the complete reference.
| Tool | Remote | Desktop | Description |
|---|---|---|---|
get_design_context |
Yes | Yes | React+Tailwind code from selection (or custom framework) |
get_screenshot |
Yes | Yes | Screenshot of current selection |
get_variable_defs |
Yes | Yes | Variables and styles used in selection |
get_metadata |
Yes | Yes | Sparse XML of selection (IDs, names, types, positions, sizes) |
get_figjam |
Yes | Yes | FigJam diagrams as XML with screenshots |
get_code_connect_map |
Yes | Yes | Figma node to code component mappings |
use_figma |
Yes | No | General-purpose write to canvas (create, edit, delete) |
create_new_file |
Yes | No | Create new Figma Design or FigJam file |
generate_diagram |
Yes | No | Generate FigJam diagram from Mermaid or natural language |
generate_figma_design |
Yes | No | Send live UI to Figma as design layers (code to canvas) |
search_design_system |
Yes | No | Search libraries for components, variables, styles |
whoami |
Yes | No | Authenticated user identity |
The primary workflow is link-based. You select a layer in Figma, copy the URL from the browser address bar, and paste it into your agent prompt. The agent extracts the node ID and calls get_design_context. The tool returns React+Tailwind code by default, or you can specify a custom framework output.
Write-to-canvas capabilities are more ambitious. The agent can create, edit, and delete pages, frames, components, variants, variables, styles, text, and images. For FigJam, it can create stickies, sections, connectors, shapes, tables, and code blocks. The agent is supposed to check the design system before creating elements from scratch. In practice, this works best when paired with a skill file that enforces design system constraints.
Supported diagram types for generate_diagram: flowchart, Gantt chart, state diagram, sequence diagram, architecture diagram, and ERD. Useful for having an agent generate architecture documentation directly in FigJam.
Figma also provides built-in skills for the plugin system: Code Connect, Build/Update Screens from Design System, and Create New File. These skills teach the agent specific Figma workflows beyond raw tool access.
Client support varies by feature. The following table shows which agent platforms support which Figma MCP capabilities as of May 2026.
| Client | Desktop | Remote | Write to Canvas | Code to Canvas | Plugin/Skills |
|---|---|---|---|---|---|
| Claude Code | Yes | Yes | Yes | Yes | Yes (Figma plugin) |
| Codex | Yes | Yes | Yes | Yes | Yes (Codex Skills) |
| Cursor | Yes | Yes | Yes | Yes | Yes (Figma plugin) |
| VS Code Copilot | Yes | Yes | Yes | Yes | Yes (Figma plugin) |
| Gemini CLI | Yes | Yes | No | No | Yes (Extension) |
| Warp | Yes | Yes | Yes | Yes | No |
Miro MCP Server: AI-Powered Whiteboarding
Miro has been developing MCP integrations that give agents access to boards. The server enables reading board content, creating shapes and stickies, and making connections between elements. Typical use cases include automated diagram generation, turning meeting notes into structured boards, and architecture documentation.
The Miro MCP server follows standard MCP server configuration patterns. Configuration for each agent platform uses the same approaches covered in section 10.2. The key difference is that Miro boards are freeform canvases, not structured design files, so agent outputs tend to be more exploratory and less pixel-precise than Figma or Paper outputs.
As of May 2026, Miro's MCP documentation is limited compared to Figma and Paper. The tool list and configuration details may evolve. Check the official Miro developer docs for the current state.
MagicPattern MCP: Generative Design Patterns
MagicPattern provides generative design patterns --- gradients, mesh gradients, blobs, patterns, and other decorative elements. The MCP server lets agents generate SVG and CSS patterns programmatically rather than browsing a UI library by hand.

This is a niche tool in the MCP ecosystem, but it solves a real problem. Background patterns, decorative dividers, and visual texture are the kinds of tasks that slow down a design workflow. Having the agent generate these on demand, with parameters you control via prompt, is faster than any manual approach.
Configuration follows the standard MCP server pattern. The server exposes tools for generating specific pattern types with parameters like color, scale, density, and seed value. Each call returns SVG or CSS that the agent can write into a design file or codebase.
Paper MCP Server: 22 Tools for Connected Canvas
Paper's MCP server runs inside the Paper Desktop app. When a file is open, the server listens at http://127.0.0.1:29979/mcp. It connects to Cursor, Claude Code, Claude Desktop, Codex, Copilot, OpenCode, and Antigravity. The setup for each platform is covered in section 10.2.
Paper exposes 22 tools --- the largest surface of any design tool MCP server. Here is the complete reference.
| Tool | Category | Description |
|---|---|---|
get_basic_info |
Read | File name, page name, node count, artboard list with dimensions |
get_selection |
Read | Selected nodes (IDs, names, types, size, artboard) |
get_node_info |
Read | Node details by ID (size, visibility, lock, parent, children, text) |
get_children |
Read | Direct children of a node |
get_tree_summary |
Read | Compact text summary of subtree (optional depth limit) |
get_screenshot |
Read | Screenshot by ID (base64, optional 1x or 2x scale) |
get_jsx |
Export | JSX for node+descendants (Tailwind or inline-styles format) |
get_computed_styles |
Read | Computed CSS styles for nodes (batch) |
get_fill_image |
Read | Image data from image fill node (base64 JPEG) |
get_font_family_info |
Read | Font availability check (local or Google Fonts) |
get_guide |
Workflow | Guided workflows (e.g., figma-import) |
export |
Export | Export nodes as PNG, JPG, SVG, MP4 with scale overrides |
create_artboard |
Write | Create new artboard with name and styles |
write_html |
Write | Parse HTML and add/replace nodes |
set_text_content |
Write | Set text of Text nodes (batch) |
rename_nodes |
Write | Rename layers (batch) |
duplicate_nodes |
Write | Deep-clone nodes with descendant ID map |
move_nodes |
Write | Reposition or reparent nodes |
update_styles |
Write | Update CSS styles on nodes |
delete_nodes |
Write | Delete nodes and descendants |
finish_working_on_nodes |
Signal | Clear working indicator from artboards |
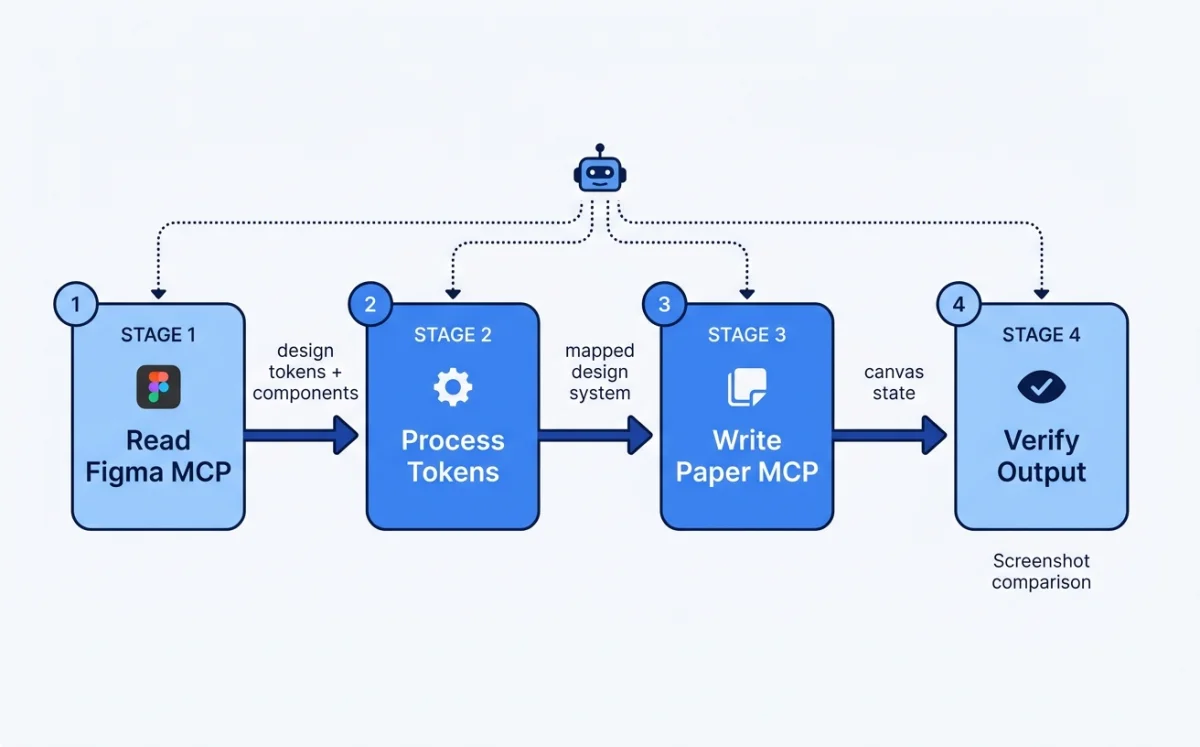
The get_jsx tool is Paper's killer feature for the design-to-code pipeline. It returns production-ready JSX with Tailwind classes directly from the canvas. No translation layer. No approximation. Paper is HTML/CSS natively, so the JSX output is a faithful representation of what is on screen. Chapter 12 covers this pipeline in depth.
The write_html tool enables the reverse direction: code to canvas. The agent generates HTML, calls write_html, and the content appears on the Paper canvas. This bi-directional flow is unique to Paper. Figma can write to canvas via use_figma, but the input format is a structured API call, not raw HTML.
My take: Paper's 22-tool MCP surface is the most complete in the ecosystem. The get_jsx tool alone saves hours of translating design to code. But the Desktop app requirement is a real limitation for Linux users and CI environments. If Paper offered a headless server mode, it would be the clear default for agentic design workflows.
Chaining MCP Servers: Multi-Tool Workflows
Multiple MCP servers can run simultaneously in a single agent session. The agent orchestrates between them using sequential tool calls. This is where MCP gets powerful --- a single agent prompt can trigger a workflow that spans Figma, Paper, Notion, and your codebase.
Three chaining patterns show up repeatedly in production use.
Pattern 1: Figma to Paper token sync. Open the design system file in Figma. Open the Paper file where you want the design system. Prompt the agent: "Create a design system in Paper that matches the Figma file." The agent calls get_variable_defs on the Figma MCP server to read colors, spacing, and typography. Then it calls create_artboard and write_html on the Paper MCP server to create the design system elements. Finally it calls update_styles to apply the tokens from Figma.
# Figma → Paper token sync workflow
# Both MCP servers active in same agent session
# Step 1: Agent reads Figma design system
# Figma MCP: get_variable_defs() → colors, spacing, typography
# Figma MCP: get_screenshot() → visual reference
# Step 2: Agent creates Paper design system
# Paper MCP: create_artboard({ name: "Design System" })
# Paper MCP: write_html({ html: "<div>...design system elements...</div>" })
# Paper MCP: update_styles({ styles: { /* tokens from Figma */ } })Pattern 2: Notion to Paper content sync. Open the Paper file with placeholder content. Prompt: "Sync the content from the Notion Testimonials database with this frame." The agent reads from the Notion MCP server, then writes the real content into Paper via set_text_content.
# Notion → Paper content sync workflow
# Step 1: Agent reads Notion database
# Notion MCP: query_database({ database_id: "testimonials" })
# Returns: [{ name: "Sarah", quote: "...", company: "..." }, ...]
# Step 2: Agent populates Paper design
# Paper MCP: set_text_content({ updates: [
# { nodeId: "name-1", text: "Sarah" },
# { nodeId: "quote-1", text: "..." },
# { nodeId: "company-1", text: "..." },
# ...
# ]})Pattern 3: Design to code and back. The agent reads a design from Figma or Paper via MCP, generates production code, then optionally writes the coded version back to the canvas for visual verification. This pattern is the foundation of the pipeline covered in Chapter 12.
# Design → Code → Canvas verification loop
# Step 1: Read design
# Figma MCP: get_design_context({ url: "https://figma.com/..." })
# Returns: React + Tailwind JSX
# Step 2: Agent generates production code
# (Agent writes files, runs dev server, verifies visually)
# Step 3: Write back to Paper for verification
# Paper MCP: write_html({ html: "<div class='hero'>...</div>" })
# Human reviews on Paper canvas
# Agent iterates based on feedbackEach MCP server uses the currently opened file as context. Figma MCP operates on whatever file you have open in the browser. Paper MCP operates on whatever file you have open in the Paper Desktop app. The agent does not switch files --- you do.
Warning: Long-running agent sessions can cause MCP connection drops. If the agent reports it cannot access a tool that should be available, restart the agent session. LLMs can also hallucinate tool parameters occasionally --- if you see repeated tool call errors, restart the session to reset the agent's tool-use context.
Web Access: Firecrawl and Exa MCP
Agents without live web access are frozen at their training cutoff. They cannot check current documentation, see what a competitor's site looks like today, or verify that a tool's API has not changed since last month. For design work, this limitation is more than inconvenient. It produces stale output. The agent references deprecated APIs, describes outdated UI patterns, and generates code that does not match the current state of the tools it uses.
Two MCP servers address this: Firecrawl for structured web extraction at scale, and Exa for quick ad-hoc web searches within a session.
Firecrawl: Structured Web Extraction
Firecrawl (128k+ GitHub stars) provides search, scrape, crawl, interact, and monitor capabilities via CLI and MCP server. In June 2026, it added installable workflows for repeatable web tasks, including deep research, SEO audits, and website design cloning (source: @firecrawl, retrieved 2026-06-04).
Install the CLI with all capabilities:
npx -y firecrawl-cli@latest init --all --browserOr add the MCP server to your agent configuration:
{
"mcpServers": {
"firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"]
}
}
}The five capabilities map to different design workflows:
| Capability | What it does | Design use case |
|---|---|---|
| Search | Web search with structured results | Find design references, competitors, and inspiration |
| Scrape | Extract content from a single URL | Capture a specific page's layout, copy, and styling |
| Crawl | Extract content from an entire site | Map a competitor's full site structure and page patterns |
| Interact | Scrape then interact with the page using AI or code | Navigate multi-step flows (onboarding, checkout) to capture all states |
| Monitor | Schedule recurring scrapes with change detection | Track when a competitor updates their design or a tool changes its docs |
The Interact capability is the most interesting for design workflows. It lets the agent scrape a page, then interact with it: click buttons, navigate flows, fill forms. This means the agent can capture multi-state UIs (empty states, loading states, error states, success states) by actually navigating through the product instead of just scraping a single page.
Exa MCP: Quick Web Search Inside Agent Sessions
Exa provides live web search directly inside agent sessions. Setup takes about 60 seconds: type /mcp in Claude Code, approve the Exa server, and the agent gains real-time web access (source: @RoundtableSpace, retrieved 2026-06-04).
Exa is for quick, ad-hoc lookups. It does not crawl or monitor. It searches and returns results. The value for design work is immediacy: the agent can verify current state without leaving the session.
{
"mcpServers": {
"exa": {
"command": "npx",
"args": ["-y", "exa-mcp-server"],
"env": {
"EXA_API_KEY": "your-api-key"
}
}
}
}When to Use Which
| Task | Use | Why |
|---|---|---|
| "What does the Stripe landing page look like right now?" | Exa | Quick single-page reference check |
| "Crawl this competitor's site and map their page types" | Firecrawl | Structured extraction at scale |
| "Check if the Figma REST API v2 endpoint has changed" | Exa | Quick documentation verification |
| "Capture all states of this competitor's checkout flow" | Firecrawl (Interact) | Multi-step navigation with interaction |
| "Alert me when this site changes its hero section" | Firecrawl (Monitor) | Scheduled change detection |
| "Find three examples of SaaS pricing pages with toggle toggles" | Exa | Search-based discovery |
Practical Workflows
Workflow 1: Competitive design audit.
You want to understand how five competitors handle their onboarding flows. The agent needs to see every screen, not just the landing page.
"Use Firecrawl to crawl these five URLs. For each site, extract:
1. The onboarding flow: every screen from sign-up to first-use
2. UI patterns used: modals, tooltips, progress bars, empty states
3. Copy tone: formal, casual, technical
4. Estimated number of steps in the flow
Summarize the patterns in a comparison table, then suggest which
patterns would work for our product."Firecrawl's crawl capability handles the scale. The agent gets structured data from every page on each site, identifies the onboarding screens, and produces a comparative analysis. Without Firecrawl, you would visit each site manually, screenshot every screen, and type notes into a document.
Workflow 2: Design cloning from a reference site.
You want to replicate the visual style of a specific site. Firecrawl's design cloning workflow extracts the styling directly.
"Scrape https://linear.app and extract:
1. Color palette (backgrounds, text, accents, borders)
2. Typography (font families, sizes, weights, line heights)
3. Spacing patterns (padding, gaps, margins)
4. Border radius values
5. Shadow values
6. Animation and transition patterns
Output as CSS custom properties I can use as a design token base."This is faster than manually inspecting elements in DevTools. The agent gets the full styling picture in one call and produces tokens you can drop into your design system.
Workflow 3: Multi-state UI capture.
You need to see all states of a competitor's pricing page: monthly vs annual toggle, different plan selections, upgrade modals, and the checkout flow that follows.
"Use Firecrawl Interact to navigate the pricing page at [URL].
1. Capture the default monthly view
2. Click the annual toggle and capture the updated prices
3. Click the Enterprise plan's 'Contact Sales' button and capture the modal
4. Click the Pro plan's 'Get Started' button and capture the checkout flow
5. For each state, extract the layout structure, copy, and visual hierarchy"The Interact capability navigates through the product like a real user. The agent captures states that a simple scrape would miss --- the toggle state, the modal state, the multi-step checkout state. This is the closest an agent gets to manual QA without a browser automation tool.
Workflow 4: Documentation verification before code generation.
Before the agent writes code that calls an external API, you want to verify the current endpoint structure.
"Search the web for the current Remotion v4.0 renderMedia() API.
I need to confirm:
1. The correct import path
2. Whether the 'codec' option is still required
3. The current way to specify output location
4. Any breaking changes from v3
Then use the confirmed API to write a render script for our
Hyperframes pipeline."Exa handles this in seconds. The agent checks the live documentation, confirms the current API shape, and writes code that matches the current version instead of guessing from training data. This prevents the common failure mode where the agent generates code for a deprecated API that no longer works.
Workflow 5: Competitor monitoring.
You want to know when a competitor updates their landing page design.
# Set up a recurring monitor
firecrawl monitor create \
--url "https://competitor.com" \
--schedule "daily" \
--prompt "Has the hero section, pricing section, or navigation changed since the last check? If yes, describe the changes. If no, respond 'no changes'." \
--notify "slack:#design-intel"The monitor runs daily. When the competitor updates their design, you get a Slack notification with a description of what changed. This is passive competitive intelligence --- you do not need to check manually, and you never miss a change.
Workflow 6: Design reference collection.
You are starting a new project and want to collect visual references for the design direction.
"Use Exa to find:
1. Five examples of developer tool landing pages with dark themes
2. Three examples of SaaS pricing pages with toggle between monthly/annual
3. Four examples of onboarding flows that use progressive disclosure
For each result, scrape the page with Firecrawl and extract:
- Screenshot URL
- Primary color palette
- Layout pattern (hero + features grid, hero + alternating sections, etc.)
- Notable design elements (animations, illustrations, 3D elements)
Organize into a reference board I can share with the team."Exa finds the sites. Firecrawl extracts the details. The agent produces a structured reference collection that replaces hours of manual browsing and screenshotting.
Security Considerations
Giving an agent live web access expands its capabilities and its attack surface. A few precautions:
- Scope Firecrawl to specific domains. Do not point a crawl at the open web. Target known competitors, reference sites, and documentation URLs. Unscoped crawling can consume credits fast and produce noise.
- Treat Exa results as unverified input. The agent trusts web search results. A convincingly-written blog post with wrong information becomes part of the agent's output. Cross-reference critical facts.
- Monitor queries in CI. If you use web access in automated workflows, log the queries. You want to know what the agent is searching for and what it finds.
- Rate-limit monitor jobs. Daily monitoring of 20 competitors is reasonable. Hourly monitoring is not. Set intervals that match the pace of actual change in your industry.
My take: Live web access should be a default, not an add-on. Every design agent should be able to check current state before generating output. The combination of Exa for quick lookups and Firecrawl for structured extraction covers the full range of web access needs in a design workflow. Install both. Use Exa daily for quick checks ("does this API still work?", "what does the current site look like?"). Use Firecrawl when you need structured data at scale (competitive audits, design cloning, multi-state capture). The five minutes of setup pays for itself the first time the agent catches a breaking API change before you ship broken code.
Generative UI: When Agents Render Live Interfaces
Everything covered in this chapter so far follows one model: the agent calls a tool, the tool returns data, and the data appears as text in the conversation. That model works for most agentic design workflows. Read a Figma file. Export JSX. Write HTML to a canvas. The agent produces code. The human reviews the code.
Generative UI inverts this. The agent does not just return data or code. It renders live, interactive components directly into the user's interface. The user clicks buttons, fills forms, drags elements, and sees real UI --- not markdown descriptions of UI. The agent decides what to show. The frontend renders it. The user interacts. The loop closes in real time.
This is a fundamentally different interaction model. Understanding it requires understanding the protocol stack that makes it possible.
The Protocol Stack: MCP, A2A, AG-UI, and A2UI
Four protocols govern how agents communicate with tools, with each other, and with users. They stack.
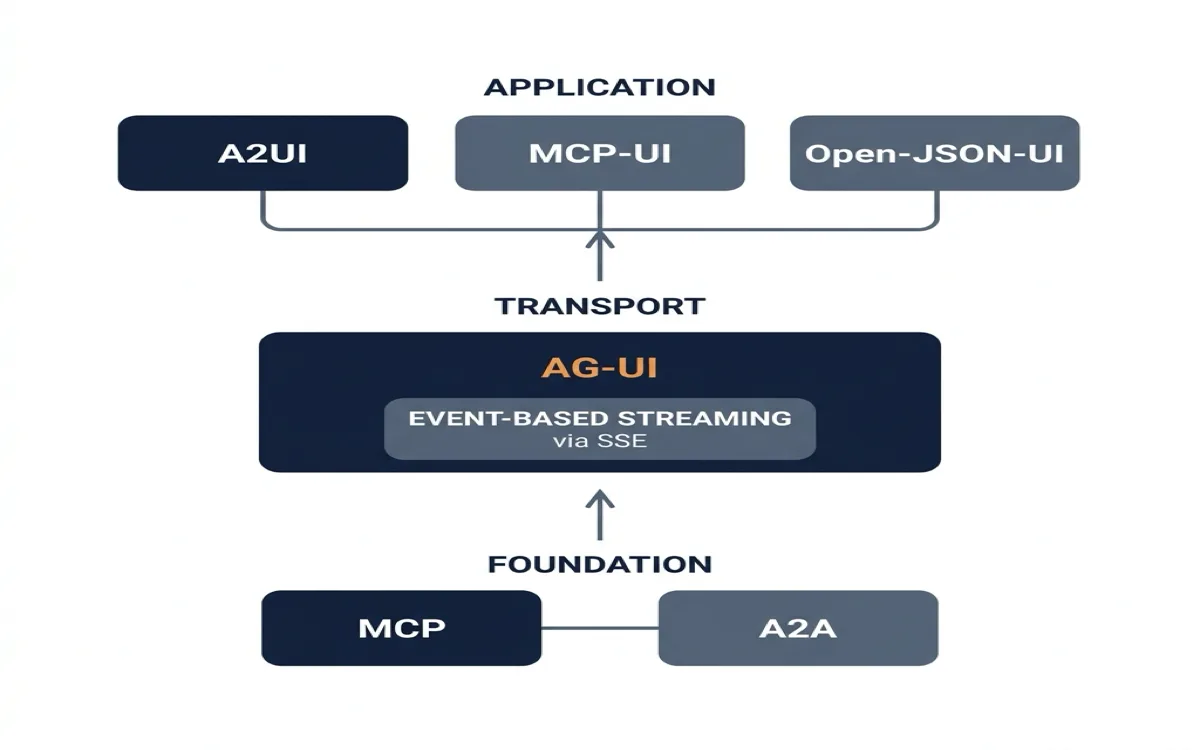
MCP (Model Context Protocol) is the foundation. It connects agents to tools and data. Every MCP server covered in this chapter --- Figma, Paper, Miro, MagicPattern --- uses MCP at the bottom of the stack. MCP is request-response. The agent calls a tool, the tool returns a result. No streaming. No user interface. Just data.
A2A (Agent-to-Agent Protocol) sits alongside MCP at the foundation layer. It handles communication between agents. Where MCP connects one agent to many tools, A2A connects many agents to each other. An A2A agent exposes an Agent Card (a JSON document at /.well-known/agent.json) describing its identity, capabilities, and endpoint. Other agents discover it, negotiate how to communicate, and collaborate on tasks. A2A uses JSON-RPC 2.0 over HTTP with SSE for streaming. It is agent-agnostic --- the agents do not need to share a framework, a model, or a vendor.
The key A2A concepts:
- Task is the fundamental unit of work. A task has a lifecycle:
submitted,working,completed,failed,canceled. - Message is one turn in the conversation, with a role (user or agent) and one or more Parts.
- Part is the smallest content unit: text, a file, or structured JSON data.
- Artifact is the output the agent produces: a document, an image, a data structure.
For design workflows, A2A enables multi-agent collaboration. A research agent can hand off findings to a design agent, which hands off a prototype to a review agent. Each agent specializes. They coordinate through A2A without sharing context windows or model sessions.
AG-UI (Agent-User Interaction Protocol) is the transport layer. It is the bridge between the agent and the user's frontend application. AG-UI is event-based and streaming. Instead of request-response, the agent emits a continuous stream of events that the frontend consumes in real time.
AG-UI uses Server-Sent Events (SSE) as its primary transport. SSE is a standard HTTP-based protocol where the server pushes events to the client over a long-lived connection. Unlike WebSockets, SSE is unidirectional (server to client) and works through firewalls and proxies without special configuration. The frontend sends user actions as HTTP POST requests. The agent responds with a stream of SSE events.
The event types AG-UI defines:
| Category | Events | What it does |
|---|---|---|
| Lifecycle | RunStarted, RunFinished, StepStarted, StepFinished | Track the agent run from start to finish |
| Text | TextMessageStart, TextMessageContent, TextMessageEnd | Stream text responses token by token |
| Tool calls | ToolCallStart, ToolCallArgs, ToolCallEnd, ToolCallResult | Stream tool invocations and results |
| State | StateSnapshot, StateDelta | Sync application state using JSON Patch |
| Reasoning | ReasoningStart, ReasoningContent, ReasoningEnd | Expose the agent's thinking process |
The critical difference from MCP: AG-UI streams. MCP is call-and-return. AG-UI is a continuous event feed. When an agent decides to render a weather card, it emits ToolCallStart (I'm calling get_weather), then ToolCallArgs (the location is Tokyo), then ToolCallEnd (done calling), then ToolCallResult (here's the data). Each event arrives separately. The frontend can render intermediate states: loading spinner while the tool runs, then the card with data when the result arrives.
A2UI (Agent-to-User Interface) is the application layer. It defines what the UI looks like in a format the agent can generate. Where AG-UI handles transport, A2UI handles content.
A2UI is a declarative, JSONL-based specification. The agent does not write React or HTML. It emits a structured description of what UI elements to show. The frontend maps that description to real components from a registered catalog. Three competing specs sit at this layer:
| Spec | Origin | Approach |
|---|---|---|
| A2UI | Declarative JSONL, streaming, platform-agnostic | |
| MCP-UI | Microsoft + Shopify | Iframe-based, extends MCP for user-facing experiences |
| Open-JSON-UI | OpenAI | Schema-based standardization of OpenAI's internal format |
These specs compete for the same layer, but AG-UI can carry any of them. CopilotKit, the primary AG-UI client implementation, supports all three.
My take: The four-protocol stack is real, but most design teams will only interact with MCP and AG-UI directly. A2A matters for multi-agent systems (covered in Chapter 11). A2UI matters if you are building a product with generative UI. For design tool integration, MCP is enough. For agent-to-user rendering, you need AG-UI. The others become relevant as your system scales.
Three Patterns for Generative UI
With the protocol stack understood, the practical question is: how does an agent actually render UI in your application? There are three patterns, and they sit on a spectrum from maximum developer control to maximum agent freedom.
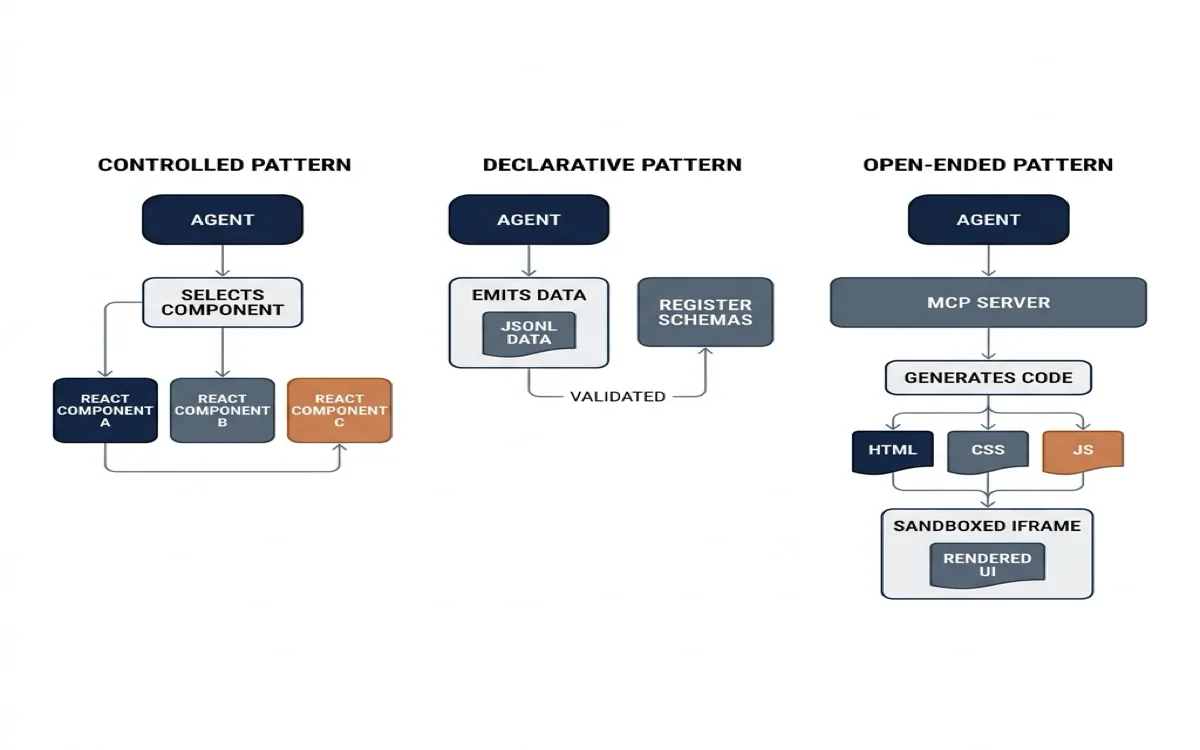
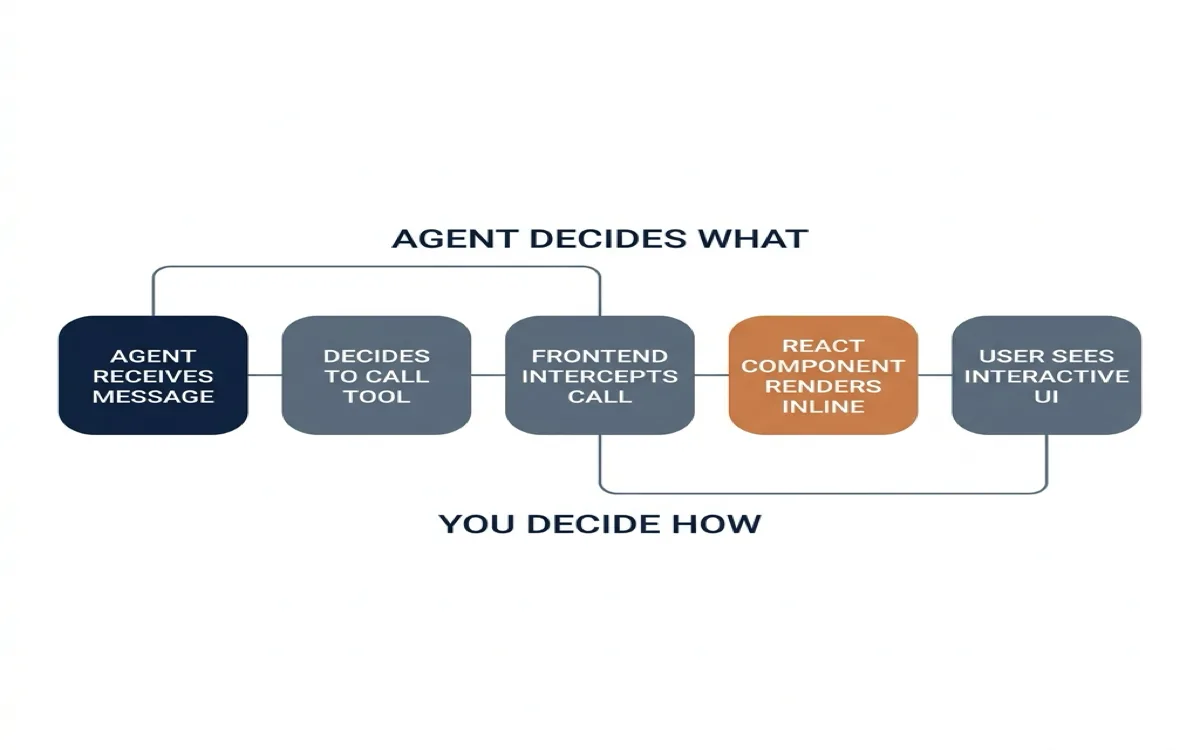
Controlled: You Build Components, the Agent Picks
In the controlled pattern, you write React components ahead of time. Each component is registered as a tool the agent can call. The agent decides which component to render and what data to pass. It cannot create components you haven't defined. It cannot change how they look. It picks from your menu.
The mechanism is tool-call rendering. When the agent calls a tool, the frontend intercepts that call and renders a matching React component inline in the conversation.
Using CopilotKit, the code looks like this:
// Register a component that renders when the agent calls "get_weather"
useRenderTool({
name: "get_weather",
parameters: z.object({ location: z.string() }),
render: ({ status, parameters, result }) => {
if (status === "inProgress") return <WeatherSkeleton />;
if (status === "complete") return <WeatherCard data={result} />;
if (status === "error") return <ErrorState error={result.error} />;
},
});Using the Vercel AI SDK, the pattern is similar but uses typed tool parts:
// Server: define the tool
const weatherTool = createTool({
description: 'Display the weather for a location',
inputSchema: z.object({ location: z.string() }),
execute: async ({ location }) => {
return { temperature: 22, condition: 'Sunny', location };
},
});
// Client: render the tool output
{message.parts.map((part) => {
if (part.type === 'tool-displayWeather') {
switch (part.state) {
case 'output-available':
return <WeatherCard {...part.output} />;
}
}
})}The agent decides what (which tool to call, with what parameters). You decide how (what component renders, what it looks like, what happens when the user clicks).
Token cost. Each registered component costs roughly 400 tokens in the agent's context window. The agent needs to know the tool name, its parameters, and its description to decide when to call it. At 25 components, you burn 10,000 tokens per turn just on tool definitions. This pattern works well for narrow, high-value flows where the UI vocabulary is bounded --- a flight booking flow, a financial dashboard, a settings panel.
Declarative: The Agent Emits a Schema, the App Composes
In the declarative pattern, you define a catalog of component schemas. Each schema describes a type of UI element: a card, a table, a chart, a form, a list. The agent emits a JSONL specification that references schemas from your catalog and fills in data. The frontend composes the actual UI from your registered components.
The difference from controlled: instead of one tool per component, there is one tool that accepts a schema describing what to render. The agent has more creative freedom --- it can combine elements, nest layouts, and compose interfaces you didn't explicitly anticipate. But it stays within the boundaries of your catalog.
A2UI formalizes this with three concepts:
- Catalog --- component definitions (Zod schemas) paired with React renderers. You register these once: "a card has a title, a subtitle, an image URL, and an action."
- Surface --- a rendered UI instance the agent creates. The agent says "I want a surface with a card and a table."
- Operations --- the agent returns
a2ui.render(operations=[...])from a tool call. Operations set components on surfaces and bind data to them.
// Register a catalog with two schemas
const catalog = [
{ schema: z.object({ title: z.string(), body: z.string() }), renderer: Card },
{ schema: z.object({ headers: z.array(z.string()), rows: z.array(z.array(z.string())) }), renderer: Table },
];
// Wrap your app
<CopilotKit a2ui={{ catalog }}>
{children}
</CopilotKit>The agent then emits something like:
{"op": "create_surface", "surface_id": "s1"}
{"op": "set_component", "surface_id": "s1", "component": "Card", "data": {"title": "Tokyo Weather", "body": "22°C, Sunny"}}
{"op": "set_component", "surface_id": "s1", "component": "Table", "data": {"headers": ["Day", "Temp"], "rows": [["Mon", "22°C"], ["Tue", "19°C"]]}}The frontend renders a Card and a Table using the registered renderers. The agent decided the layout and the data. You controlled the visual identity and behavior through your catalog.
Token cost. Flat. One tool definition regardless of how many component types exist in the catalog. The schema is small and reusable. This is why the declarative pattern scales better than controlled when you have dozens of component types.
A2UI supports two flavors. Fixed schema: you author the catalog, the agent supplies data. Dynamic schema: a secondary LLM generates component definitions at runtime. Fixed schema is the safer default for production. Dynamic schema is useful for prototyping when the UI vocabulary is still evolving.
Open-Ended: The Agent Writes Raw HTML
In the open-ended pattern, there is no catalog. No schema. The agent writes HTML, CSS, and JavaScript. The frontend renders it in a sandboxed iframe.
MCP-UI formalizes this. An MCP server registers a tool and links it to an HTML/JS resource. When the agent calls the tool, CopilotKit fetches the resource and renders it as a sandboxed iframe inside the conversation. The iframe can talk back to MCP tools over postMessage.
// MCP server registers a tool with linked UI
server.registerTool("search-flights", {
inputSchema: { origin: "string", destination: "string", date: "string" },
_meta: { "ui/resourceUri": "ui://flights/flights-app.html" },
}, handler);
// The linked HTML/JS resource
server.registerResource("flights-app", "ui://flights/flights-app.html", {
mimeType: "text/html+mcp",
}, () => ({ contents: [{ text: htmlContent }] }));When the agent calls search-flights, CopilotKit mounts the HTML app inside the chat. The user can click through a multi-step booking wizard. The app talks back to MCP tools via postMessage.
The open-ended pattern has the most expressive range. It can render anything a web page can render: charts, maps, drag-and-drop boards, games. But it has three serious drawbacks:
- Brand inconsistency. Without a design system constraining output, every render looks different. The agent's HTML does not inherit your application's styles or tokens.
- Security surface. Sandboxed iframes limit the damage, but the agent's HTML runs arbitrary JavaScript. This is not acceptable for user-facing production features.
- No persistence. The iframe's state dies when the conversation moves on. There is no way to save the user's interaction state across turns.
Use open-ended for internal tools, throwaway visualizations, and one-off data exploration. Do not ship it to users.
Choosing the Right Pattern
| Criterion | Controlled | Declarative | Open-Ended |
|---|---|---|---|
| Component count | ≤10 well-defined components | 10-100+ component types | Unlimited, ad-hoc |
| Brand consistency | Guaranteed (you wrote every component) | High (catalog constrains output) | None |
| Token cost per turn | ~400 tokens per tool (scales linearly) | Flat (one tool, many schemas) | Low (one iframe) |
| Engineering effort | High (component per capability) | Medium (catalog registration) | Low (MCP server ships HTML) |
| Agent creativity | Low (picks from menu) | Medium (composes from catalog) | High (writes anything) |
| Security | Same origin, full control | Catalog-controlled, safe | Sandboxed iframe, risky |
| Best for | High-value flows, pixel-perfect UI | Products with many content types | Internal tools, throwaway viz |
The decision tree is simple.
If you have pixel-perfect mockups and a defined component library, use controlled. You know exactly what every state looks like. The agent connects the dots.
If you have dozens of card types, table variants, chart layouts, and form configurations, use declarative. The catalog scales without exploding token costs. This is the right default for most production applications.
If you need a one-off chart for a meeting or an internal data viewer, open-ended is fine. Just don't ship it.
Case Study: A Design System Dashboard with Controlled Pattern
Imagine you maintain a design system with 80 components. You want an internal dashboard where team members can ask an agent questions about the system in natural language and see live component previews.
You register six tools, each with a corresponding React component:
// Tools registered with the agent
const designSystemTools = {
"search_components": { renders: ComponentListCard },
"show_component_detail": { renders: ComponentDetailPanel },
"compare_components": { renders: ComponentComparisonTable },
"show_token_usage": { renders: TokenUsageChart },
"show_accessibility": { renders: A11yReportCard },
"show_responsive": { renders: ResponsivePreview },
};A designer types: "Show me all button variants and their accessibility status."
The agent calls two tools: search_components with {query: "button variants"} and show_accessibility with {component: "Button"}. Two React components render inline: a list of all button variants with links to Storybook, and an accessibility report card showing contrast ratios and keyboard behavior for each variant.
The designer clicks a button variant in the list. The agent calls show_component_detail with the selected variant. A detail panel expands inline with the component's props, variants, design tokens, and a live preview.
Everything the user sees is a React component you built. The agent never generates unfamiliar UI. But the interaction feels conversational: the user asks in natural language, the agent orchestrates the right components with the right data.
Case Study: A Product Catalog with Declarative Pattern
Now imagine an e-commerce assistant. The product catalog has 50,000 items across 200 categories. The UI vocabulary is large but structured: product cards, price tables, comparison grids, review summaries, filter panels, and cart widgets.
Building 200+ controlled components is impractical. Instead, you register a catalog of 12 component schemas:
const catalog = [
{ schema: "product_card", renderer: ProductCard },
{ schema: "price_table", renderer: PriceTable },
{ schema: "comparison", renderer: ComparisonGrid },
{ schema: "review_summary", renderer: ReviewSummary },
{ schema: "filter_panel", renderer: FilterPanel },
{ schema: "cart_widget", renderer: CartWidget },
{ schema: "image_gallery", renderer: ImageGallery },
{ schema: "size_selector", renderer: SizeSelector },
{ schema: "spec_table", renderer: SpecTable },
{ schema: "availability", renderer: AvailabilityBadge },
{ schema: "recommendation", renderer: RecommendationRow },
{ schema: "order_summary", renderer: OrderSummary },
];A customer asks: "I need running shoes under $150 with good arch support."
The agent emits a JSONL specification:
{"op": "create_surface", "surface_id": "search-results"}
{"op": "set_component", "surface_id": "search-results", "component": "filter_panel",
"data": {"filters": [{"type": "category", "value": "Running Shoes"}, {"type": "price_max", "value": "$150"}, {"type": "feature", "value": "Arch Support"}]}}
{"op": "set_component", "surface_id": "search-results", "component": "recommendation",
"data": {"items": [{"name": "Nike Pegasus 41", "price": "$140", "rating": 4.6}, {"name": "Brooks Ghost 16", "price": "$140", "rating": 4.7}]}}
{"op": "set_component", "surface_id": "search-results", "component": "comparison",
"data": {"headers": ["Feature", "Nike Pegasus", "Brooks Ghost"], "rows": [["Cushioning", "React X", "DNA LOFT"], ["Drop", "10mm", "12mm"], ["Weight", "9.4oz", "9.8oz"]]}}The frontend renders a filter panel, a recommendation row, and a comparison grid. The agent composed these from the catalog. The visual consistency comes from your registered renderers. The agent had the creative freedom to decide that a comparison grid was useful for this query and to compose it with the filter panel.
The token cost is the same whether the catalog has 12 schemas or 200. One tool. One definition. Many possible compositions.
Case Study: An Internal Data Explorer with Open-Ended Pattern
An analytics team needs an internal tool where agents can generate ad-hoc visualizations from database queries. The team does not want to pre-build chart types. They want the agent to invent the right visualization for each query.
They set up an MCP server that exposes a run_query tool linked to an HTML visualization resource. When the agent runs a query, the MCP server returns both the data and a rendering script. CopilotKit mounts the result in a sandboxed iframe.
An analyst asks: "Show me the conversion funnel by traffic source for the last 30 days."
The agent calls run_query with the SQL. The MCP server returns the data and an HTML/CSS/JS visualization that renders a Sankey diagram. The analyst sees a live, interactive chart inside the conversation.
This works because the visualization is throwaway. Nobody will reuse this Sankey diagram. It answers one question and disappears. The open-ended pattern is correct here because the UI vocabulary is unbounded and the output does not need to match a brand system.
But if the same analyst asks "build me a dashboard I can share with the CEO," the open-ended pattern fails. The dashboard needs consistent styling, responsive behavior, and persistence. That requires the controlled or declarative pattern.
How This Relates to Agentic Design
Generative UI is not just "agents making UI." It is a structured interaction model with specific protocols, patterns, and trade-offs.
For the agentic design workflows covered in this book, generative UI matters in two places:
- Design tool interfaces. Paper's canvas is already an HTML surface. An agent with AG-UI could render live component previews inside Paper, not just write HTML to a static canvas. The designer sees the agent's output as real UI, not code that needs to be previewed separately.
- Design system dashboards. Teams maintaining design systems can build conversational interfaces where anyone asks questions about tokens, components, or patterns and gets live rendered answers. The controlled pattern guarantees every response looks like it belongs to the design system.
The protocol stack also clarifies where MCP ends and generative UI begins. MCP connects agents to tools. AG-UI connects agents to users. If you want the agent to render UI in your application, you need AG-UI on top of MCP. If you only want the agent to call tools and return data, MCP alone is sufficient.
My take: The declarative pattern is the one most design teams should bet on. It gives agents enough creative freedom to compose useful interfaces while keeping the visual output inside your design system boundaries. The controlled pattern is overkill for most products unless you have a small, well-defined set of flows. The open-ended pattern is a trap for anything customer-facing. Start with A2UI's fixed schema flavor. Expand to dynamic schema only when the UI vocabulary outgrows what you can pre-define.
Resources: See AG-UI Protocol for the event specification and SDKs. See CopilotKit for the primary AG-UI client implementation. See Vercel AI SDK for the alternative tool-call-to-component approach.
Troubleshooting MCP Connections
MCP connections fail in predictable ways. Here is a troubleshooting reference for the most common issues.
| Symptom | Cause | Fix |
|---|---|---|
| Agent says MCP tool is not available | Agent session started before MCP server was configured | Restart the agent session |
| Agent session cannot connect to Paper MCP | Paper Desktop app is not running or no file is open | Open Paper Desktop and ensure a file is loaded |
| Paper MCP connected but agent reports no access | MCP host tool needs restart | Restart the MCP host (Paper Desktop app) |
| Figma MCP returns errors on large designs | Large, deeply nested designs exceed response limits | Select specific frames instead of entire pages |
| Figma SVG fills returned as images | Known Figma MCP behavior | Use get_design_context for code output instead |
| Paper MCP fails on Windows WSL | WSL cannot access 127.0.0.1:29979 |
Enable mirrored mode networking in WSL config |
| MCP limits not reset after Paper plan upgrade | Desktop app caches plan limits | Update Paper Desktop app and restart |
| Repeated tool call errors from agent | LLM hallucinating tool parameters | Restart the agent session |
I spent an hour debugging an MCP connection before I realized the Paper Desktop app was not running. The error message was generic --- "connection refused" --- which pointed me toward network issues instead of the obvious cause. Start with the basics: is the tool running, is a file open, is the server listening?
Figma MCP has additional quirks. It ignores spacer elements. It does not convert inset borders to outlines. Code Connect components are not reliably converted. These are known limitations as of May 2026 and will likely improve over time. For now, work around them by selecting specific frames and validating the output.
My take: MCP connection issues are the number one source of frustration when starting with agentic design. The tools work well when they work, but the failure modes are silent and confusing. I recommend keeping a terminal tab open with a test MCP call ready to paste. When the agent reports a connection issue, verify independently before spending time on agent-side debugging.
Next: With MCP servers configured and connected, the next question is scale. How do multiple agents collaborate on a single design? Chapter 11 covers multi-agent design teams, the orchestrator pattern, and when parallelizing is worth the complexity overhead.